There exists a multitude of ways we humans learn. We learn by actively manipulating our environment and observing what happens; by associating two events together and assuming some kind of causality; by learning through our culture and teaching; by reactively changing our behavior as a result of an event; and by heart or through dialogues.
While comparable, the mechanisms behind these approaches are not all the same. Different situations require different approaches – but all of them allow us to acquire new understanding, knowledge, behaviors, skills, values, attitudes and preferences1. Or in other words, all of these approaches allow us to learn. And it’s not much different for machines!
Categories of machine learning
Depending on the situation, goal and type of data, a different kind of learning strategy needs to be selected to develop a machine learning model. This article explores the three main categories of how machines can learn. These are:
- Task-driven supervised learning
- Data-driven unsupervised learning
- Behavioral-driven reinforcement learning
The main difference between these three categories is the availability of the desired target data. In other words, can the AI verify if it did the right thing or not – and if so, how can it do this?
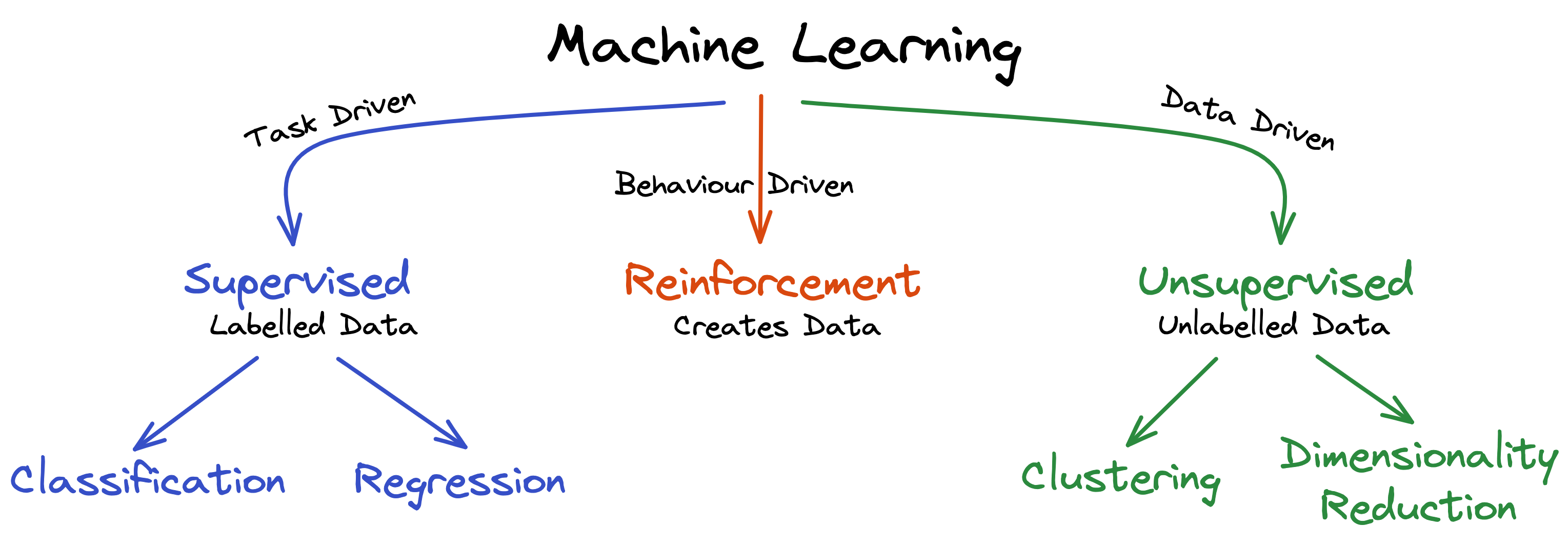
Supervised learning
In supervised learning, the model knows the target label. For example, it knows if a given photo contains a picture of a cat, or how much a specific house costs. Based on that, the model can then be trained to detect new cats and estimate the price of new houses.
The term ‘supervised’ comes from the fact that if we know what the outcome should be, then we can validate if the answer is correct; just like in school when a teacher asked us to identify a country on a map of the world. The teacher always knew the correct answer and supervised us to help us to get to the right answer. Similarly, a supervised learning model can always look up the right answer and see how well it does.
Unsupervised learning
In unsupervised learning, there is no target label. In other words, the correct answer is either not known or doesn’t exist. Therefore there is no teacher with the right answer who can tell the student what to look for.
However, these models can be tasked to find meaningful structures in the data and shed some new insights on a topic. For example, unsupervised models can be used to group documents into unique clusters, or find other customers that have similar tastes to you – and as a consequence recommend to you what ‘like-minded people’ also preferred.
Returning to the school analogy, unsupervised models are like group brainstorming projects or presentations in front of the class. Seemingly chaotic distributed knowledge is combined in a structured way to make the overall topic more approachable and easier to grasp. As such, there isn’t a clear right or wrong way, just one that is more or less insightful in the end.
Reinforcement learning
In reinforcement learning, the situation is much different compared to the previous two categories. Here, the model is an active agent in its environment and creates labels by being punished or rewarded for its actions. In contrast to the other two categories, reinforcement learning is especially good at learning long sequences of actions to reach a specific goal. For example, such models can be used to train a humanoid robot to autonomously traverse difficult terrain, to train a self-driving car to navigate itself on the road, or to teach a machine to play board and video games better than we humans do.
Here, the school metaphor doesn’t fit; it’s as if the AI actually skipped school to go outside to play basketball. Through playing the game and learning by trial and error, the student improves their skills in playing basketball. It’s the same for the AI: by being in a reactive and stimulating environment, the AI creates its own data through its behavior. ‘Good actions’ lead to positive outcomes (reward) and ‘bad actions’ lead to negative outcomes (punishment). As such, the ‘correct answers’ didn’t exist at the beginning but were created by the AI through ‘doing things’.
Supervised learning
Most of the time when people talk about AI or machine learning, they actually mean supervised learning. As we’ve discovered, this type of learning can be done when the available data comes with a clear target label i.e. when we know exactly what kind of values the AI model should predict. And the goal of such an AI is to minimize prediction errors to be as close to the correct answer as possible.
Examples of supervised learning tasks are:
- Having photos of handwritten numbers (the data is stored in the image as pixels) and knowing what they represent (the label i.e. the numbers 0 to 9), we can predict what number (the target label) a never-seen-before handwritten scribble represents.
- Having X-ray images (the data is stored in the image as pixels) and knowing if a patient develops cancer (the label i.e. ‘yes’ or ‘no’), we can predict if an X-ray of a new patient has cancer or not (the target label).
- Knowing the characteristics of a house (the data is stored in the house description e.g. how many rooms, location, parking spot etc.) and knowing how much it costs (the label i.e. 350’000 CHF), we can predict how much a new house should cost (the target label).
The target label can come in multiple forms: it can be categorical (e.g. ‘cat’, ‘dog’, ‘bird’), binary (e.g. ‘yes’ or ‘no’) or continuous (e.g. 3’120 CHF, 72.3 kg, 22 months).
If the label can be put into a ‘bucket’ (i.e. distinct groups with clear boundaries), as is the case for categorical and binary labels, then the model is performing a classification task. In other words, it is capable of saying if something is like things in bucket A, B or C.
If the label is a number on the number line, like it is for continuous values, then the model is performing a regression task. In other words, it is capable of saying how much something is.
To better understand the difference between these two approaches, let’s consider the following tasks:
| Classification | Regression |
|---|---|
| What kind of disease does a patient have? | How much time will a patient take to recover? |
| Will a customer come back? | How much will a customer spend? |
| Does the photo contain a picture of a pedestrian? | How far away is the pedestrian in the photo? |
| Will credit card fraud happen? | How much credit card fraud will happen? |
We will cover the topics of Classification and Regression in more detail in the following articles.
Unsupervised learning
When our dataset doesn’t provide any target labels to measure the AI’s performance against – if we don’t know the content of photos or the price of houses, for example – we usually choose unsupervised learning. The goal of unsupervised learning is to find useful structures in datasets that we can exploit.
While unlabelled data is much more common than labelled data, understanding such models is much harder, and a major challenge of unsupervised learning is evaluating whether the model learned something useful.
But in those cases where unsupervised models work well, they are very powerful. For example:
- If we want to analyze the different topics discussed on social media, we could take all of the information about each individual post (the dataset) and ask an unsupervised model to group similar looking posts together. This helps us to either find posts that we might have missed in a particular group, or label every entry in the group with the corresponding discussed topic by reading through just a few samples.
- If we wanted to know the viewing preferences of ourselves and millions of other people (the dataset being which movies we’ve watched), but we don’t have labels for each viewer (nobody is a ‘only-horror-watcher’ or ‘prefers-animals-talking’), then unsupervised learning models can allow us to identify other movie watchers that have similar preferences – which gives us the opportunity to recommend movies watched by like-minded people.
- If you have the travel information of millions of people passing through an airport (a dataset containing a huge amount of information per traveler e.g. age, nationality, time of departure, airplane type taken, destination, food preference), you can use unsupervised learning to reduce the dimensionality of the dataset. Reducing it to two or three dimensions allows you to visualize each traveler as a single point. Such an approach can help to identify groups of similar travelers and also identify unusual travellers, so-called outliers.
In the first example, the goal was to take the unlabeled dataset and group similar objects into buckets, but without knowing or needing any label on these buckets to do the sorting. In machine learning terms, this procedure is called clustering.
In the second and third examples, the goal was to take a high dimensional dataset (i.e. a dataset that has lots of information about each individual object or sample in this dataset) and ultimately reduce this dimensionality to something more useful, where samples that are similar to each other are also close to each other in this new data space. This process of restructuring the data into something more meaningful and potentially easier to understand is called dimensionality reduction.

Unsupervised learning is a very important tool for the beginning of any machine learning project, as it allows the exploration of the dataset and identification of underlying structures. This step helps us better understand a dataset and provides useful insights into the potential for following up with a supervised learning approach. For this reason, unsupervised learning is often also performed as an exploration approach on datasets where the target labels would be available.
We will cover the topics of Clustering and Dimensionality Reduction in more detail in later articles.
Reinforcement learning
Reinforcement learning is quite different from the other two categories of machine learning, as it revolves around taking actions. While training data is available from the start in supervised and unsupervised learning, it is absent in reinforcement learning.. The algorithm needs to decide how to act in order to achieve a specific task, but in the absence of training data, the algorithm learns from experiences. Through continuous rewards and punishments (i.e. this action was good, that action was bad), the AI learns what kind of actions to favour over others, with the goal being to maximize long-term rewards.
Much more than just finding the right label (supervised learning) or finding an underlying structure in the data (unsupervised learning), reinforcement learning is about finding the right sequence of actions to reach this goal. It’s about learning to make the right decisions one after the other.
The most well-known example of this is an AI that can play board or video games. In such a scenario, the AI is an active player who learns to make the right moves to score points and to avoid the moves that cost points or result in losing the game. Such a model’s capability was most famously shown through DeepMind’s AlphaGo, which was able to beat the world champion in the highly complex (at least for humans) board game Go.
In contrast to the other two categories, reinforcement learning is still a quite new machine learning category and is mostly used in research settings. This is due to the fact that to train such an AI we need thousands of iterations in a controlled environment, which usually implies a simulated computer environment where time can be sped up – unlike the unpredictability and chaos of the physical world.
We cover this topic in more depth in the article Reinforcement Learning.
The in-between categories of semi and self-supervised learning
The lines between supervised and unsupervised learning are not always clear and there exists a few additional learning strategies that fall somewhere between them. In particular these are semi-supervised and self-supervised learning.
Whereas semi-supervised learning is an approach where an ‘unlabeled’ dataset is used for supervised learning, self-supervised learning is an approach where ‘labeled’ data is used for unsupervised learning.
Semi-supervised learning
Labeling huge amounts of data is usually very time consuming, which is the reason why we sometimes try to find an in-between solution by manually labelling as many instances as we can manage. As a consequence, we end up with a dataset that has mostly unlabeled data, but for which we know the correct label for at least a few instances.
In such a case we can use a semi-supervised learning approach, where we try to combine supervised and unsupervised approaches to assign the most likely label to the instances where we don’t yet know the label.
For example, a semi-supervised approach is used when your smartphone or computer groups your personal photos, suggests a few labels, and within no time has identified every person in your photo collection. This approach of first grouping, asking for a few labels, and then using supervised learning to get the labels of all data points is also used in the domain of Natural Language Processing and automatic speech recognition, where getting a fully labeled dataset is otherwise very costly.
Self-supervised learning
Self-supervised learning refers to an unsupervised learning approach that is framed as a supervised one. More precisely, it describes an approach where the dataset itself can be used as the target label.
For example, it is these kinds of models that are used to colorize old black and white photos, remove noise from images, or to restore lost sections of paintings. By using the lower quality version of the data as the input (e.g. black and white photos, noisy images, paintings with missing sections) and the desired higher quality version of the data as the output, the AI can learn how to correct these flaws and to improve the quality of the input data itself.
Other examples of such self-supervised models are autoencoders or generative adversarial networks (GANs), which are also the technology behind DeepFakes and other content generating or manipulating AI technologies.
So what did we learn?
We have learned that machine learning models can be broadly grouped into three main categories: supervised, unsupervised and reinforcement learning. We also learned that the biggest difference is if the model has access to the output label or not (supervised vs. unsupervised), or if the model creates the input data and outcomes itself through its behavior in a rewarding and punishing environment.
While the creation of datasets with output labels is often a very laborious manual process, supervised learning models are nonetheless preferred as they are much better understood than other models, and their performance can be easily measured. So if you have a dataset and can create the output labels (potentially with the help of semi-supervised learning), then you should try to do so.
Unsupervised learning models are usually used to explore a new dataset and to identify particular and interesting structures in the data. If the outcome labels are available, an unsupervised approach is often the best first step for any data analysis, and can help to better solve a later supervised learning task.
However, the reason that most current AI applications are supervised models is not because they are better, it’s simply because they are better understood. The vast amount of data that exists all around us is unlabeled and unprepared – finding ways to analyze and use such data for machine learning, without labeling it first, is considered by some AI researchers as the dark matter of artificial intelligence.
It means that this kind of data is much more common than labeled data and that we can’t claim to truly understand the universe – or in this case artificial intelligence – without finding a way to work with this data too.