Natural language processing (NLP) is a subfield of artificial intelligence, computer science and linguistics concerned with giving computers the ability to process natural human language, hence the name. More precisely, it’s about creating AI models capable of understanding and generating text and speech on a par with humans.
Although talking with a computer sounds more like science fiction than reality, it is actually something that most of us already do on a regular basis. Have you ever used a computer to translate text from one language to another? Has your navigation device already told you to “turn left at the next junction”? Have you ever dictated a text message to the voice assistant on your smartphone rather than typing it? What about interacting with a chatbot on a website to clarify your needs or ask a question? Well, all of these tasks are undertaken by an AI system from the NLP domain.
Let’s take this a stage further. What about talking and listening to an intelligent machine that understands the meaning of words, can tell creative and captivating stories, or can just listen to what we have to say at the end of a long day before giving us some sage advice that only a good friend can give. Although we’re not there yet, NLP is the domain that will take us on this journey.
In many instances, we actually won’t need an ‘intelligent’ AI capable of using language on a human level. It might already be enough to have an AI that allows us to interact with it and other humans using human language, even if such an AI wouldn’t truly understand the concepts behind it.
The AI of a self-driving car doesn’t need to know the detailed inner workings of an engine or the exact difference between apple and pear trees in order to function well enough to avoid such obstacles. In reality, the AI only needs to know how to navigate the environment it finds itself in by reacting to external information in a way that delivers a safe and reliable experience to the human user.
Similarly, an AI in the NLP domain doesn’t need to understand the meaning of an apple, as long as it can understand and use this word in the right context so that the human user believes the AI understood its true meaning.
How does NLP work?
In two previous articles Data Comes in Many Forms and Everything Is Data!, we learned that everything can be data. As long as it can be put into numbers, an AI model can learn from it and work its magic.
For example, if we know a person is 178cm tall, weighs 75kg, and is 34 years old, we can encode this data as 178, 75 and 34. Or if we have a digital image of a person, we can just take the color values of each pixel and use these numbers as data for the vision AI model.
But what should we do when we encounter text? For example, how would you transform the following sentence into simple numbers that a machine can understand?
Switzerland loves chocolate and cheese.
The solution to solve this conundrum is called word embedding.

Word embedding
In the context of NLP, word embedding means we take each word and represent it as a single point in a high-dimensional space. Similar to how each geographic location on Earth has a unique two-dimensional GPS coordinate, each word from a given text will have a unique high-dimensional coordinate – the tricky part is finding the right high-dimensional space to represent each word in a sensible way. The process of putting these words into that space is called embedding, hence the name.
As you might have guessed, the goal of the AI is to create this high-dimensional space in such a way that relationships between words in text form are still preserved in this space as relationships between points.
To illustrate this concept a little better, let’s imagine we want to embed each word from the sentence “Switzerland loves chocolate and cheese” in a three-dimensional space. We may end up with something like this:
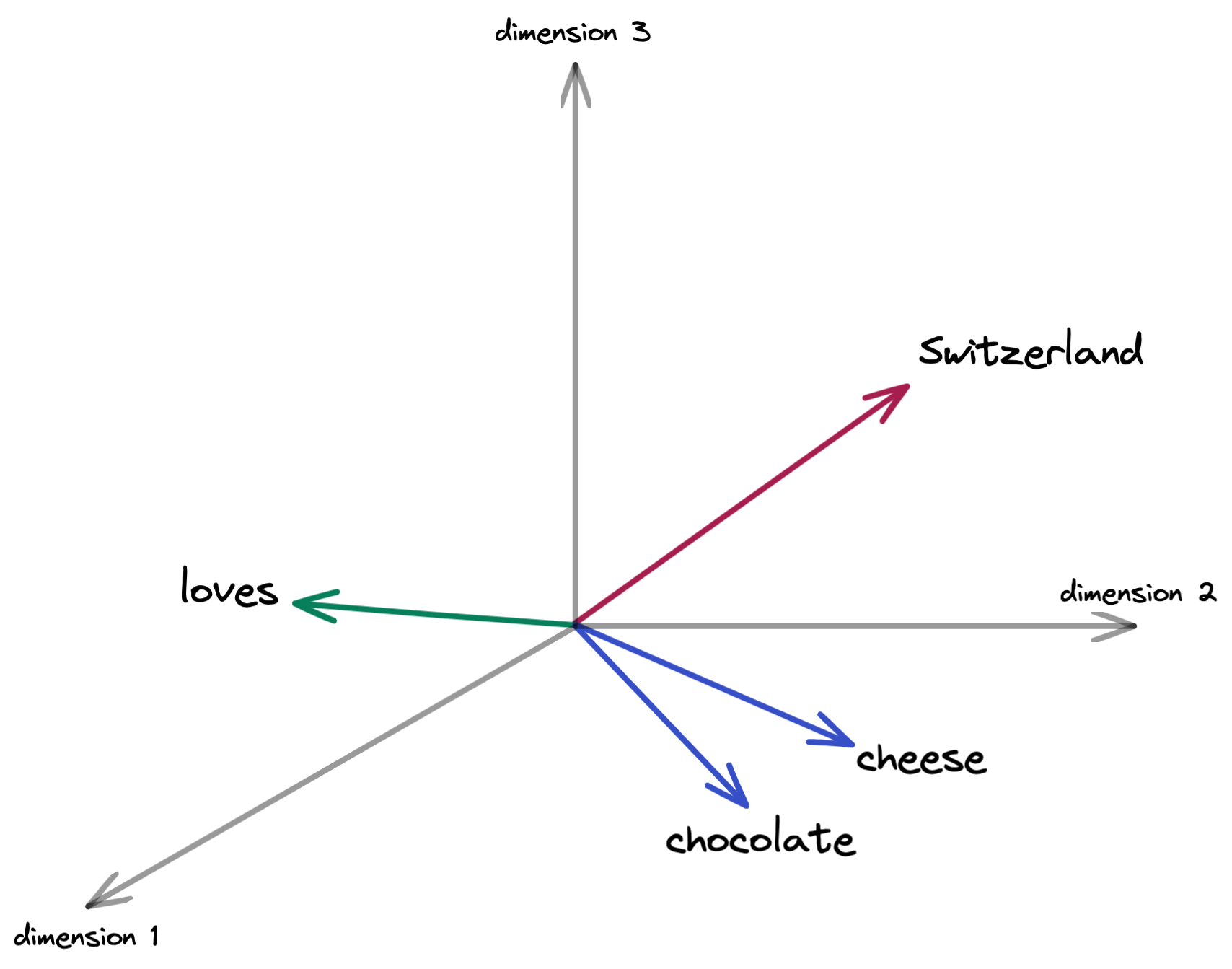
What we can take from this figure are the following things:
- The words
Switzerlandandlovesare usually not strongly associated, which is why they are in different locations of this three-dimensional space. - Given that chocolate and cheese are delicious food items, they should be close to each other in this three-dimensional space.
- Given that chocolate and cheese are also associated with Switzerland (in direction of dimension 2) and
loves(in direction of dimension 1), both of these food items should equally be in the direction of dimensions 1 and 2.
Keep in mind that neither dimension 1 or 2 stand directly for Switzerland or loves – the AI just established these dimensions in such a way that they help preserve the relationships between the words of “Switzerlan loves chocolate and cheese”. To put it another way, this high-dimensional space is capable of ‘embedding the words’ in a meaningful way. Learning how to create this high-dimensional space and at what location to put each individual word is exactly what the AI model tries to learn.
Word2vec
As you may remember from your classes in school, a point in a multi-dimensional space can also be represented as a vector, where each coordinate indicates how much in one direction the point lies.
That’s why one of the more famous and prominent ways of creating such word embeddings is called the Word2vec (read as ‘word to vector’) routine. The goal of this routine is to take any word from a given text and give it an appropriate vector.
In this context, however, an ‘appropriate’ vector also depends on which part of the language’s meaning we want to represent. For example, we could say that words with the same gender are on one side of the high-dimensional space, e.g. man and king versus woman and queen. At the same time, the distance between the points king and man should be the same as the distance between the points queen and woman, as is visualized in the following illustration:

In a similar way, but with a completely different relationship, we might want to embed verbs and adverbs, such as play and playful, and joy and joyful:

Now let’s imagine a third scenario where we would like to clump all of these human terms together and have them as far away as possible from non-human terms like robot or AI:

Visualizing and understanding each of these ‘themed’ spaces is not too difficult for humans. But what if the task was now to combine all of these three themes (and many more) into one single high-dimensional space capable of representing 100,000 words, with all their relationships?
As you can imagine, this becomes very difficult, very quickly; it’s not really a task for our human mind. Luckily however, it is easily managed by an AI if it has enough data to learn from.
But even if we hand this task over to an AI, there are a few important things to consider before we ask it to create such a high-dimensional word embedding space:
- What are the words we have in our dataset? Finding the right high-dimensional space also depends on which words need to be represented. For example, does the dataset contain ‘only’ the works of Shakespeare, or is it the full corpus of the English language over the past 500 years?
- How many dimensions do you allow the word embedding model to use? The more dimensions, the more specific relationships can be established – but the higher the dimensions, the higher the computational demand to establish this embedding space.
- How many different ‘themes’ (i.e. linguistic aspects as shown in the illustrations above) do you intend to represent in your embedding space?
Context matters
The Word2vec routine was established in 2013 and helped to unlock great achievements in the NLP domain. Suddenly it was possible to represent word associations in a meaningful way that computers were able to understand – i.e. the word embedding vectors – and all of this without the need for manual human intervention. It almost seemed as if the AI models learned what words actually ‘meant’ from the data.
But the problem with this word embedding approach is that it is context-independent. In other words, it doesn’t know in which context a word appears, it doesn’t consider other words in a sentence, or even what other words are coming before or after a target word. Therefore the same word will always be encoded at the same point in the space. This is a problem, because language is very much context-dependent. Consider the following three sentences:
- Teddy Roosevelt once fought a bear barehanded.
- Bear in mind to take the right flight of stairs.
- Oh, so you “lost” my teddy bear on the flight?
According to simple Word2vec word embedding, the words “teddy”, “bear” and “flight” would always fall on the same point in the embedding space.
To solve this issue, more advanced AI models were developed which were capable of taking the context in which a word appears into consideration.
Currently, the most advanced of these techniques is called a Transformer. Explaining the details of these AI models goes beyond the scope of this article, but what is important to know is that Transformer models are contextual-sensitive, meaning that they can embed a word in this high-dimensional space (i.e. create a word vector) that considers the context in which the word appears in the sentence.
What kind of tasks can NLP do?
Thanks to these two methods – word embedding (with Word2vec) and context-embedding (with Transformers) – AI models are capable of doing remarkable things. Given the right data, such AI models can learn to create a meaningful high-dimensional space in which all words of a given text dataset (e.g. the full English language) are sufficiently well embedded, along with consideration of meaning and context.
Remember: the main reason for creating such an embedding space is to transform human language from its text form into numbers (i.e. a vector) – a format that a computer understands and can work with. Once we have an AI that can transform words into numbers, we can go a step further and use these numbers to train another AI to perform amazing NLP tasks.
Let’s take a closer look at a few examples.
Name entity recognition
The goal of name entity recognition is to extract meaningful information from text, such as location, people, organization, dates, or just simply knowing what parts of the text are verbs, nouns, etc. To better illustrate this, let’s have a look at the following example:

Once you have an AI model capable of identifying these different entities, you can go a step further and ask it to do many things with it – such as replace some entities in the text with similar ones, for example. So Switzerland can become England, train can become plane, and Teddy Roosevelt can become Amelia Earhart.
Taking this a step further, once the AI ‘understands’ the different entities and knows how they relate to each other, it is only a small step to ask it to summarize the passage into fewer words. For example:
A famous person had a confusing dream on a visit to a European country.
Sentiment analysis
AI can also be taught to assess the sentiment of a text, i.e. the emotional state in which the text is written. It’s this approach that allows companies to quickly separate angry customers from satisfied ones, or that helps to grade the quality of a restaurant. Some social media platforms use such an approach to detect suicidal tendencies in their users and subsequently provide supportive content.
Sentiment analysis can also be used to further enrich the information about a text by trying to identify if it contains things about attitudes, emotions, sarcasm, confusion, or suspicions. So in addition to the previously mentioned context-specific word embedding, an AI can also learn how to add additional emotional states – therefore making the language embedding and subsequent AI models even more powerful.
Machine translation
Assuming there is enough data, an AI can learn to create individual embedding spaces for every language in a dataset – but in such a way that words representing the same meaning are embedded at the same location in all of the language’s individual embedding spaces.
This means that the translation from one language to another one becomes a much easier task. First, you need to embed the text from one language into the embedding space. Second, you look up what these points mean in the embedding space of the other language. And that’s it (more or less)! That’s how current state-of-the-art AI models are able to translate text between 104 different languages in the blink of an eye.
Speech recognition
So far we have only considered text, i.e. language in written form. As stated at the beginning, NLP is about language in general, which also includes spoken language. The automated translation of words from audio recording into text is called speech recognition, or speech-to-text.
We’ve already found with written text that the tricky part of understanding spoken language is to first get the data into a format that the computer can understand. In the context of speech recognition, this procedure is even more complicated, as we first need to understand what word was spoken in an audio recording before we can embed this word in the appropriate high-level embedding space.
There are multiple ways to analyze speech data, but the most frequent ones are to either look at the height of the waveform showing the oscillation of the pressure wave that creates the sound (top figure), or at the frequency power spectrum (bottom figure) where individual frequencies are separated vertically (i.e. sounds with a high pitch are shown in the top of the frequency plot, and sounds with a low pitch are shown at the bottom):
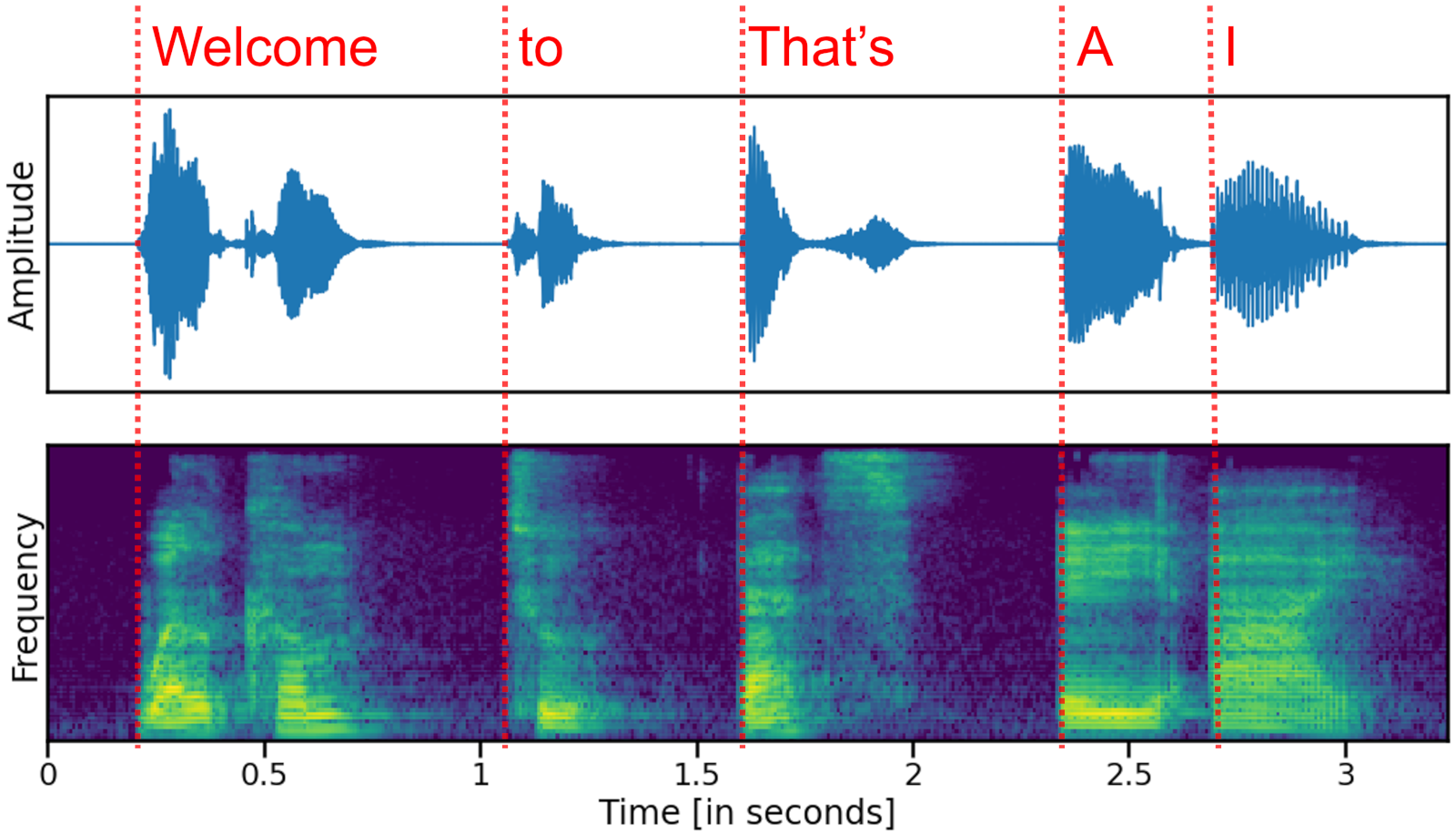
In short, an audio signal can be looked at as a very quickly changing time series signal, like the stock market (top) or a visual image like a ‘photo of what was said’ (bottom).
What these representations have in common is that in both cases, audio is represented as numbers – either as a quickly changing number on a horizontal line, or as a pixel number in an image. And so once more, now that the audio data is represented in a numerical form, an AI can ‘understand’ and work with it.
Nowadays, speech recognition is all around us and is required for any kind of voice interface with technology. If you’ve dictated a text message to your smartphone or computer, asked Siri, Alexa or Google Assistant for directions (and listened to their answer), or have been surprised at how well your phone’s microphone can filter out ambient noise and only transmit your voice, then you have encountered the wonders of speech recognition.
However, the tricky part with speech recognition is that human speech is everything but uniform. Each of us has our own way of saying things, a unique dialect, with a fast or slow speed, low or high pitch, with nasal, slurred or clear pronunciation, varying ways of word emphasis and intonation, and so forth. A reliable AI capable of speech-to-text processing needs to be able to consider all of these heterogeneous cases.
Natural language generation
Natural language generation can be seen as the opposite of putting written or spoken words into the embedding space. It’s much more about taking some information from this embedding space and creating text or speech from it (in the later example, this is also called text-to-speech). It’s this text-to-speech approach that services like Siri, Alexa and Google Assistant use to talk to us.
While creating an artificial human voice or letting an AI finish writing a sentence might sound like a very difficult task for an AI, it is actually not much more difficult than what we’ve already examined. It’s just that this time, instead of putting words into the context-sensitive embedding space, the AI learns how to take them out again.
Consider, for example, the following short sentence:
Most Swiss people ____ chocolate!
Because you have already heard all of these words in multiple contexts and have some ‘background information’ about the concepts of Switzerland, people and chocolate, it should be easy to fill in the blanks.
The same strategy can be used for AI models: by providing numerous sentences in which random words were removed and letting the AI learn how to fill in the gaps, it can generate the missing words. From there it is only a small step to ask the AI to continuously fill in the blanks at the end of the sentence. In other words, the AI can learn how to write based only on the words that were written before.
Application of NLP
NLP is currently one of the hottest topics in AI research, with multiple new applications being developed every month. Let’s focus on a few…
Automatic text summarization
As we’ve seen, NLP models can learn to reduce the size of a text to something much smaller, more compact and to the point. The goal is to train an AI to identify the most important entities and topics in the article and summarize it down to just a few sentences. In a world of ever-growing and overflowing information, having a digital information curator and summarizer can be a very helpful tool.
Spelling and grammar checker
We have all encountered a spelling or grammar checker when writing text, something that looks like this:
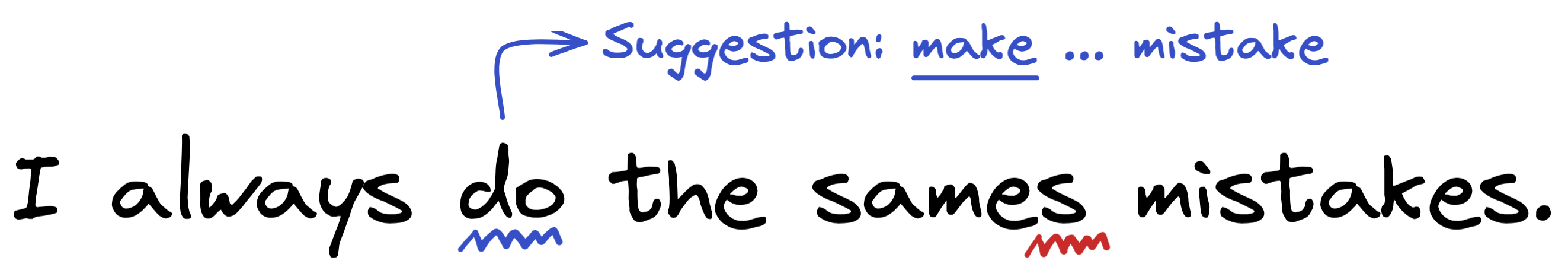
While this technology felt a bit awkward a few years ago, spelling and grammar checkers in text writing applications on computers and smartphones have become more and more sophisticated over time. They now help us on a daily basis to prevent multiple embarrassing typos in our emails and documents.
Document classification
NLP models can also be used to help big entities like hospitals, government or libraries sift through millions of documents to quickly order, sort and archive them, or group them into useful clusters depending on the content of the documents. Such an approach also contributes to how big online search engines are capable of finding the most appropriate homepage for a given search term.
Optical character recognition (OCR)
Optical character recognition (OCR) describes the process of transforming images of handwritten, typed or printed text into digital text. In other words, OCR is how we get text from a book into a computer.
OCR has been around for decades; it’s this technology that allows your bank to automatically read the handwritten orange or red payment bills, helping multiple companies to shortcut the laborious task of manual transcribing.
To better explain OCR, take a look at the following handwritten note. Can you read what it says, or by whom it was written?

While the handwriting is rather smooth, there are nonetheless a few places where it is difficult to decipher the text, particularly if we’re not used to that kind of style. What is great about OCR is that such an AI model can be trained on this author’s particular handwriting (or on similar looking ones) to quickly and precisely identify the words written by the author.
So if we ran a sufficiently trained OCR model on the previous image, we might receive the following output:

The image is of a handwritten statement by Albert Einstein, written in November 1922 during a visit to Tokyo. The quote says: “A quiet and modest life brings more joy than a pursuit of success bound with constant unrest.”
Challenges with NLP
Examining the impressive list of things NLP models can do makes it clear that this technology has already come a long way – yet there’s still much more ground to cover. For example, even though language generation has advanced, it’s not yet perfect – and perfection might be something NLP needs to strive for before being fully accepted.
Natural language and communication through text and speech is so fundamental to what makes us human, to the point where we’ve all developed an ‘ear’ for detecting if something is off. If somebody speaks slightly less enthusiastically than usual, we can hear this and might ask them, “How are you doing today?” If somebody uses more aggressive words than would be appropriate in a given situation, we might take it personally and say, “Hey, what’s the problem?”
Context is crucial, but the full context is not always available and the true intent of a speaker might be obscured. Furthermore, there is so much hidden meaning that can only be ‘read between the lines’ – in some situations ‘words are just not enough’ and ideally you will need to ‘walk in somebody else’s shoes’ to ‘truly understand’ what they meant to say. Plus there are multiple other things that can make language interpretation even more complicated: sarcasm, idioms, metaphors, homonyms, homophones and more.
All of this should make it clear that developing an AI capable of human-level language remains a difficult task, because as long as the AI is not fully covering all of these points, it will sound ‘off’ – appearing artificial and as such unpleasant, or worse unfriendly to our ear.
Once AI overcomes this hurdle, we will truly be in a new era! It will herald a time where we might forget that we’re talking to a machine; where voices of long lost loved ones can be recreated; and where new content can be generated on the fly.
Imagine a time where you can tell an AI to “Create a one-hour long talk about penguins targeted to 10-year-olds”, and where you can ask the AI to take your voice, change it to the one of a beloved cartoon character, and translate it into 20 different languages at once.
While the capability of such an AI model might sound fascinating and impressive, it should also become clear very quickly that this is a dangerous new technology. With the arrival of such advanced NLP models (which might only be a few years away), the creation of more addictive entertainment would become much easier. Misinformation could be spread even quicker than before, and the border between what is real and what’s not would become even more blurred.
For this reason, being informed about the capability of such AI models and understanding how they work is important and will hopefully help us to take action and responsibility in how these new technologies are developed as they integrate into our lives.