In our previous articles, we’ve outlined what can and cannot be classed as artificial intelligence (AI), have examined how algorithms influence our daily lives, and provided examples of how the AI learning process compares to its human equivalent.
Now it’s time to consider the fundamental building blocks of AI. So far, we have looked at what AI technology can achieve and the different ways in which we can observe it. But what is actually needed to make it function properly?
Put simply, there are four main blocks that form the backbone of AI:
- Data
- Machine learning algorithms and tasks
- Computing power
- Human expertise
One simple way to think of AI is this: “Humans using data to train machine learning algorithms on computers, with lots of computing power, to solve a specific task”. But what does that sentence really mean?
Recent successes in AI technology can be attributed to several phenomena that are closely related to these four building blocks: the rise of the internet; social networks; technological breakthroughs; and significant theoretical advances in science.
To have a real understanding of these building blocks, the following have to be considered: why do they work together now? Why couldn’t they work together before? And what else has made them a success today?
Data
Nowadays, the word “data” appears in many job descriptions on recruitment websites. In fact, plenty of people now work almost exclusively on data-related tasks. They collect it, transform it, visualize it, store it, and sell it.
Indeed, data is said to be the world’s most valuable resource,1 and one of those reasons revolves around AI, which needs data to learn. Data can be recorded by humans, sensors, machines, and apps. But what does it actually look like?
Every observation we make holds information and once it is recorded, either on a piece of paper, a hard drive, or a photo, it becomes data. Data is the recording of information in a quantitative and qualitative form, which is stored for later use. In fact, the terms “information” and “data” are often used interchangeably.
For humans or AI to learn from data, it needs to be representative and exhaustive – a quality and quantity approach is needed. If not, the learning process will most likely be compromised and lead to results that are inaccurate and biased.
For example, an AI system trained to predict the weather will not be able to give accurate forecasts of a cold winter week if it has only been given data from two weeks’ worth of summer weather patterns. It has never encountered a full seasonal cycle in the learning process, and so it would have a hard time finding patterns of data related to the whole year. However, a single year with a rainy summer would not be representative either. So ideally we would want to have more samples from several years.
As a matter of fact, even simple algorithms can perform complex tasks with ease if they are given sufficient data to learn from – increase the amount of data and you will see an increase in performance. It shows to a certain extent that the data is more important than the complexity of the algorithms used to train an AI system.
This is often called “the unreasonable effectiveness of data” – the name comes from the title of a research paper about this observation,2 which also gave birth to the phrase “big data”. This effectiveness has become more apparent in recent years as additional data is available thanks to the rise of the internet. Billions of people now share and access information every day.
Data, though, has also received a helping hand from recent significant advances in how we store it. Back in 1956, you would need an IBM RAMAC 305 computer, which weighed over a ton, to store just five megabytes of data – that’s roughly the size of a six-minute song.
{kind=link}
By the 1980s, you could store the exact same amount of information using four floppy disks weighing in total around 100 grams. Needless to say, today’s standard SD memory cards weigh two grams and can store more than 128 gigabytes (over 25,000 songs)3 on a piece of plastic the size of a stamp.
According to a report from consultancy firm Pricewaterhouse Coopers – and as seen in this infographic – the accumulated digital universe of data in 2020 totalled 44 zettabytes (one zettabyte = one million million gigabytes).
But the quality of data is just as important as the quantity. Take our previous example – a system trained with weather data from Switzerland will not be able to forecast weather in the Sahara Desert, regardless of the amount of historical records at its disposal. The AI system would have never been exposed to temperatures above 40°C, it is biased towards the Swiss mountain climate, and wouldn’t generalize with climates it doesn’t know. And that would be an issue even if decades of historical records were available.
Similarly, an opinion poll conducted at 3pm on a Thursday afternoon in a park is not representative of the overall population of a country. The people interviewed are likely to be senior citizens, parents taking care of their children, or people working from home or night shifts. The poll will almost entirely exclude the large part of the population that works a typical nine-to-five job.
Given the importance of data and the integral role it plays with AI, we will cover these aspects in more detail in a later article: Data comes in many forms. Now, though, let’s look at algorithms and tasks.
Machine Learning Algorithms and Tasks
Machine learning algorithms, whose foundations lie in statistics and mathematics, are the blueprints of how learning takes place. These algorithms, also referred to as models, analyze data in an agile way to find the best method to execute a task successfully. This process of finding the best setup (based on patterns found within the data) is what we call “learning”.
Our previous article, AI: More Than ‘Just’ a Program, discussed how modern machine learning algorithms differ from static, human written, rule-based algorithms with regards to their ability to learn from data and the patterns within it. Machine learning algorithms will iteratively change how they operate in order to improve their performance.
This process is known as the learning phase, or training phase, of the model – and it is quite similar to how humans learn. A good analogy is a driving license theory exam, where a student has to decide what actions to take in a series of real-life driving scenarios.
One way to prepare for the test would be to take lots of practice quizzes and learn from their feedback. By being exposed to a wide range of possible situations, the student could improve their understanding of the traffic rules and thus be better prepared for that final test. But the final test questions would then need to be sufficiently different from the practice quizzes to ensure that learning by heart isn’t a viable strategy.
Training a machine learning algorithm happens in exactly the same way. In the first step, the model is trained on one data set, called the training set. Then in the second step, it is evaluated separately on another, unseen data set, called the test set.
The ultimate goal is for it to perform equally well with the training set as with the test set. This ensures the model did not just memorize the details of the training set – it needs to prove it can handle new, unseen data equally well.
Why training models isn’t so straightforward.
So how can models learn? And how can they be trained? Well, let’s take our earlier article (Peek behind the curtain) as an example, which looked at how to predict the weight of children using their height and other features.
In that story, our simple model had one internal parameter (a numerical value), and the model had learned the best parameter value of 0.35 directly from the data. For some models, this direct approach of calculating the best parameters exists.
Another way to identify the best parameter is through repeated feedback and by making incremental improvements. You could start from a random parameter value – let’s say 0.1 – which we saw leads to a fairly poor performance from the model. But if you gradually increase the parameter, it would eventually get close to the optimal value of 0.35 and therefore improve the model step by step. There is potential to initially overshoot a bit, but that would reduce the performance of the model, meaning footsteps would need to be retraced to reach the optimum value of 0.35.
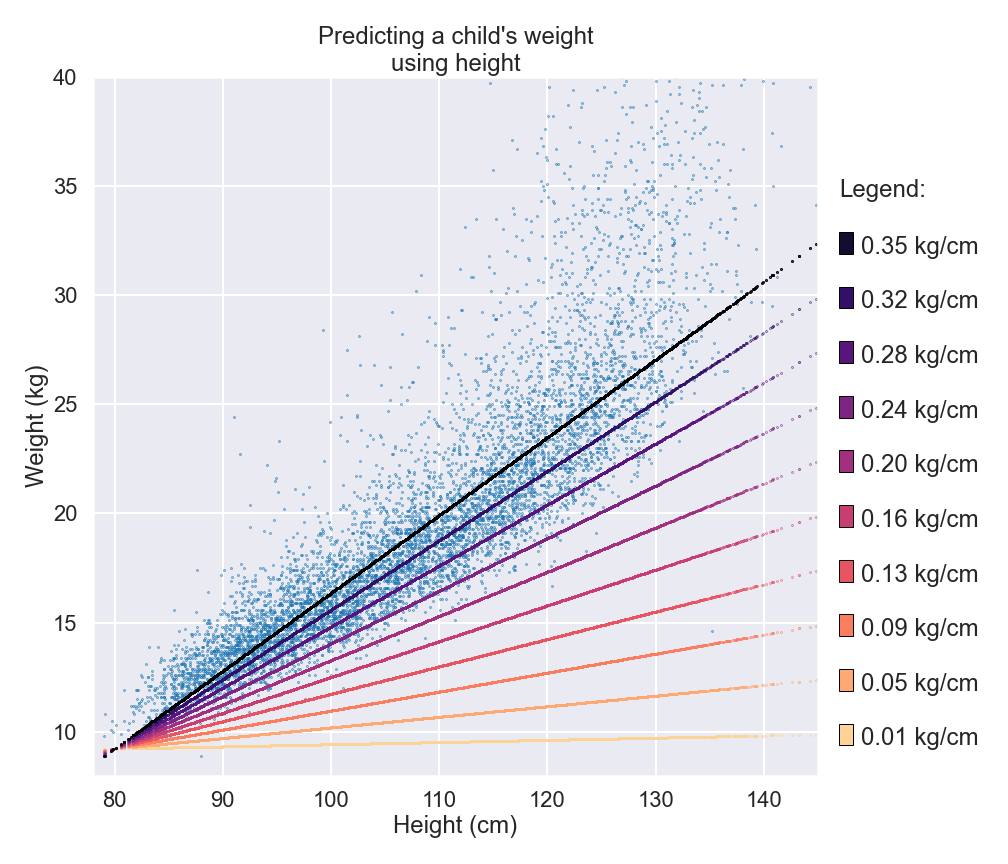
But how can we tell if the model is improving when we change the parameter? The answer comes from the data.
Firstly, it provides our target (the true weight of the children), and secondly we use it to make predictions with our interim model. That way we can calculate by how much our predictions are off-target and hence assess whether our model improved.
Thanks to this feedback, we can incrementally improve our parameter – and as a result our model gradually learns to do better. Us humans go through the same process when answering questions on a quiz, for example; we adjust our understanding whether we get the answer right or not the first time around.
In reality though, models are much more complicated and have many more internal parameters. But the key idea remains the same: we train our model by repeatedly evaluating our current predictions (our latest answers) against the target (the correct answers4), and we learn from our mistakes as to how to adjust the parameters to gradually build a better model. Along the way, the machine learning algorithms could carry out billions of calculations involving the data set in order to find the best model.
But as tasks get more complex, models require more parameters. As a result, the number of possible combinations of parameters rises accordingly – which can lead to the equivalent of looking for a needle in a haystack the size of Switzerland. So we might not find suitable parameters for our model to perform sufficiently well.
The good news is some models still succeed. To give you an idea, a recent very successful model – called Generative Pre-trained Transformer 3 (GPT-3)5 – can perform many tasks related to text understanding, but at the staggering price of 175 billion parameters!
Of course, there’s more than one way to harness data. There’s a variety of machine learning algorithm families that treat data in different ways,6 and as such have different rules for using parameters – but what they all share in common is this trainable property. Choosing one family over another will be a matter of domain expertise, characteristics of the data, and of course the particular task.
Let’s explore three different families of machine learning algorithms a bit more – the rule-based approach, the similarity approach and the data specific approach.
Rule-based Approach
For example, how easy do you think it would be to try and predict if a person will go hiking or go to the cinema? What if the only information available to make the prediction is some basic personal details and a weather forecast?
A rule-based machine learning approach would look for if-then-else rules in the data. The data might show us that if a person is over 70 years old, then they are more likely to go and catch a film, regardless of the weather. Otherwise, if it’s sunny, then people are more likely to go hiking.
Similarity Approach
Another strategy is to assume that people who are alike will behave similarly. If two individuals are of a similar height, weight, age, gender, and enjoy similar hobbies and jobs, would they want to spend their spare time doing the same activities?
This is the similarity approach, which tries to group those considered alike with each other.
Data Specific Approach
The type of data being used by a task might also influence the choice of model family. For example, working with images requires an algorithm that can take advantage of the patterns particular to images, and some models7 have been specifically developed to address this.
Computing Power
In the previous section, we covered how training a machine learning algorithm can come at the cost of a gazillion calculations in order to find the perfect parameters. The amount of resources needed to carry out these calculations can be substantial, and they have become available thanks to dramatic improvements in storage and computing capabilities over the past decades.
We have already addressed how storage has evolved, so let’s now take a look at computing power.
The power of computers plays a crucial role when it comes to data and algorithms. The brains of a computer is its CPU, or central processing unit, which was invented by the Hungarian-American mathematician, physicist, computer scientist and engineer John von Neumann in the middle of the 20th century. And it is just as important a component now as it was back then.
A CPU’s capacity dictates how many calculations and how much data processing can be carried out within a second, and thus how long computations will take to finish. A popular way to increase that capacity nowadays is parallelization, when multiple CPUs are used simultaneously to analyze the data.
In the past 50 years, the capacity of single CPUs has doubled roughly every two years – this is often referred to as Moore’s Law.8 An analogous trend can be observed for the amount of computations required by groundbreaking AI systems up to around 2012.
Since then, however, many engineers and data scientists have utilized graphical processing units (GPUs), which were initially developed for rendering high-end graphics in video games, to significantly speed up the calculations required by many advanced machine learning algorithms. This approach has since become mainstream, and some companies even develop their own custom processing units to further boost and accelerate the training of AI models.
This means the computations necessary to develop advanced AI systems now doubles roughly every three to four months, instead of every two years. As a result, we are seeing growth over 50 times faster than Moore’s Law. A new era of AI development has truly begun.
So, taking into account computation time, let’s estimate the cost for the GPT-3 model (with its 175 billion parameters) that we discussed earlier. The estimated computation time would be more than 300 years – this means that if you were to train this model on a powerful personal computer at home, you would need to wait roughly 300 years before the training actually produced a satisfactory result.
Financially, that translates into an estimated cost of $4.6million. Training such powerful models nowadays comes with a steep computation and financial cost and leaves an ever-growing carbon footprint.9
In contrast, the computer used by the Apollo 11 crew to safely land their ship on the moon in 1969 had less processing power than a modern-day mobile phone. This puts into perspective how complex the task of training the GPT-3 model is and how difficult it remains for a machine to understand text.
It would be easy to think that these complexities make training new models too much of a challenge, but help is now at hand thanks to the cloud. Instead of spending money on expensive infrastructure, companies can instead rent it in these data centers. This approach makes machine learning accessible to many businesses – but it is still only the wealthiest of organizations and individuals who can today train huge models that are the equivalent to the GPT-3.
Human Expertise
For AI to really succeed though, it needs one very important element: human expertise and guidance.
Take a project manager at a hospital, for example, who has been tasked with developing an algorithm that can predict whether a patient has contracted COVID-19 using radiology reports. The goal is to create an algorithm that could help to quickly identify positive cases within thousands of newly available written reports. Let’s take a closer look at how human expertise guides the development of the AI model.
The first task for the project manager would be to collect the appropriate training data. This involves meeting the engineers who know where the radiology reports are stored in the data warehouse, and how to gain access to them. Discussions would most likely need to take place with privacy committees to ensure only anonymized data is used, as opposed to personal data.
Data quality and diversity will have to be considered. Does it have duplicates, errors or missing values? Is it equally balanced across ages, genders, and pre-existing health conditions? It should also be free of unwanted biases that could shift predictions unintentionally towards one category over another. For example, if the patients represented in the training data all have the same hair color when they are diagnosed as having coronavirus, then the model might naïvely and falsely associate having that hair colour with contracting COVID-19.
Medical reports on their own will not get you very far – they need to be annotated to get the most out of them. The project manager would need to review these reports with a group of radiologists and ask them to indicate which ones have tested positive or negative for the virus.
To prevent annotation errors, multiple radiologists would need to review each report, and validate and verify their integrity. They would need to highlight any conflicting information or disagreements, and offer solutions for them. They would also play a crucial role in determining whether accurate predictions are even feasible with the data at hand.
Once that training data has been combined with the annotations from the radiologists, it’s time for data scientists to take over. Their job is to prepare the data for training the algorithms and finding the best parameters, as discussed throughout this article. The challenge is clear: the machine learning algorithm should predict the diagnosis for every potential COVID-19 patient as accurately as possible.
Data scientists and radiologists will work on an overall objective, plan how to evaluate the algorithm’s performance, and set a reasonable target. There are many decisions to make while doing this: for example, what happens if the model predicts a patient has COVID-19 when they are actually healthy, or vice versa? What is a reasonable target for the quality of the predictions? Being 80% right? Or 90%? What could be the impact? This stresses the importance of human reasoning and intervention – no machine can solve these issues. It is an inherently human question.
After the model is trained, domain experts, along with data scientists, will scrutinize its results and develop challenging tests to ensure the model is stable and trustworthy before it is deployed. They will analyze model failures in order to identify weaknesses or areas for improvements, and will eventually retrain the model again and again.
All those stages highlight how much human expertise is needed during the process; only when they have been completed will it be time to deploy the new AI model. Human decision making is the scaffolding behind every model – and every user of the model needs to be mindful of this.
That’s why AI researchers have recently proposed a way to store and share this information on model cards,10 just like the identity cards many of us carry. These cards consist of a rigorous list of facts and technical details about the model: the data used to train it; how it was evaluated; its intended usage; as well as ethical considerations and known caveats. An example of a face detection model card, including the list of model characteristics and descriptors, can be found here.
These cards attempt to open the black box that is associated with AI. By providing quantitative evaluations and transparency, they point out shortcomings, suggest potential improvements, and facilitate discourse around AI systems and their use. And of course these cards and their associated models will evolve over time as user feedback identifies more biases, weaknesses, or successful applications of the model.
All in all, it’s important to remember that a well balanced cohesion of data, machine learning algorithms, computing power, and human expertise is crucial to create a successful AI system.
-
The world’s most valuable resource: Data and the new rules of competition, The Economist. Picture Article May, 6th 2017. ↩
-
A number that needs to be changed every few months. ↩
-
There are tasks where the AI system does not receive a solution or target against which to evaluate its performance, e.g. when it is grouping all photos of people that look alike. But we will discuss this in a more advanced topic. ↩
-
Linear regressions, decision trees, support vector machines, random forests, neural networks… ↩
-
These models are known as convolutional neural networks. ↩
-
Moore’s law is an observation named after Gordon Moore, co-founder of Intel, who in 1965 suggested that the number of transistors in a dense integrated circuit doubles about every two years. Because his conjecture turned out to be valid, it is referred to as a “law” now. ↩
-
Training a single AI model can emit as much carbon as five cars in their lifetimes. ↩
-
First introduced in Model Cards for Model Reporting (Margaret Mitchell et. al., 2019). ↩
{kind=link}