Dans nos précédents articles, nous avons décrit ce qui peut et ne peut pas être classé comme de l’intelligence artificielle (IA) et avons examiné comment les algorithmes influencent notre vie quotidienne. Nous avons également mis en lumière dans quelles conditions le processus d’apprentissage de l’IA peut ressembler ou non à son équivalent humain.
Il est maintenant temps de comprendre ce qui se cache au cœur de l’IA. Jusqu’à présent, nous avons examiné ce que la technologie de l’IA peut réaliser et les différentes manières qu’elle a de faire partie de nos vies. Mais que faut-il réellement pour qu’elle fonctionne correctement ? Si l’on simplifie un peu, il y a quatre blocs principaux qui constituent le coeur de l’IA :
- Les données
- Les algorithmes d’apprentissage machine
- La puissance de calcul
- L’expertise humaine
Une façon “simple” de se représenter l’IA est la suivante : “L’Homme et son expertise permettent à des algorithmes (d’apprentissage machine) d’apprendre des tâches spécifiques en leur soumettant beaucoup de données, et à l’aide de fortes puissances de calcul.” . Mais que veut vraiment dire cette phrase ?
Les récents succès de la technologie de l’IA peuvent être attribués à plusieurs phénomènes étroitement liés à ces quatre éléments de base : l’essor d’Internet, des réseaux sociaux, certaines percées technologiques et des avancées théoriques importantes en science. Nous tâcherons aussi de mettre ces récents succès en perspective avec notre époque : pourquoi ces quatre éléments ne pouvaient pas marcher ensemble avant ? Et qu’est-ce qui a fait leur succès aujourd’hui ?
Les données
Aujourd’hui, le mot “données” apparaît dans de nombreuses offres d’emploi sur les sites de recrutement. De nos jours, le cahier des charges de nombreuses personnes est presque exclusivement constitué de tâches liées aux données. Que ce soit pour les collecter, les transformer, les visualiser, les stocker ou encore les vendre. On dit que les données sont la ressource la plus précieuse du monde,1 et c’est notamment parce qu’elles sont indispensables à tout processus d’apprentissage d’une IA.
Les données peuvent être enregistrées par des humains, des capteurs, des machines et des applications. Mais, à quoi ressemblent-elles réellement ? Chaque observation que nous faisons contient des informations et une fois qu’elles sont enregistrées, que ce soit sur un morceau de papier, un disque dur ou une photo, elles deviennent des données. Les données sont l’enregistrement d’informations sous une forme quantitative et qualitative, qui sont stockées pour un usage ultérieur. En fait, les termes “informations” et “données” sont souvent utilisés de manière interchangeable. Référence à [everything-is-data] ici
Pour que les humains ou l’IA puissent tirer des enseignements des données, celles-ci doivent être à la fois représentatives et exhaustives - on parle donc du besoin d’avoir une approche qualitative et quantitative. Sinon, le processus d’apprentissage de l’IA sera très probablement compromis et conduira à des résultats inexacts et/ou biaisés.
Par exemple, un système d’IA formé à la prévision de la météo ne pourra pas donner de prévisions précises sur une semaine froide en plein hiver s’il n’a reçu que des données pendant deux semaines de plein été. N’ayant jamais été confronté à un cycle saisonnier complet dans le processus d’apprentissage, ce système aurait naturellement du mal à trouver suffisamment d’informations pour modéliser la météo pendant une année entière. Cela dit, une année entière mais avec un été pluvieux ne serait pas non plus représentative. L’idéal serait donc de disposer d’un plus grand nombre d’échantillons provenant de plusieurs années.
En fait, même des algorithmes qualifiés de “simples” peuvent accomplir des tâches complexes facilement si on leur donne suffisamment de données pour en tirer des enseignements : augmentez la quantité de données et vous constaterez une amélioration des performances. Cela montre, dans une certaine mesure, que les données sont plus importantes que la complexité des algorithmes utilisés pour entraîner un système d’IA.
On appelle souvent ce phénomène “l’efficacité insensée des données” (‘l’expression vient du titre d’un papier de recherche qui fait justement cette observation)2 - et elle a également ouvert la voie au domaine des “données massives”. Cette efficacité insensée est devenue plus évidente ces dernières années, car de nombreuses données supplémentaires sont désormais disponibles en raison de l’essor de l’internet. Aujourd’hui, des milliards de personnes partagent et consultent des informations chaque jour.
Il ne faut pas oublier non plus que les données ont également bénéficié de récentes avancées très significatives dans la manière dont nous les stockons. En 1956, il fallait utiliser un ordinateur IBM RAMAC 305, qui pesait plus d’une tonne, pour stocker seulement cinq mégaoctets, soit à peu près la taille d’une chanson de six minutes.
{kind=link}
Dans les années 1980, on pouvait stocker exactement la même quantité d’informations en utilisant quatre disquettes pesant au total environ 100 grammes. Il va sans dire que les cartes mémoire SD standard d’aujourd’hui pèsent deux grammes et peuvent stocker plus de 128 gigaoctets (soit plus de 25 000 chansons)3 sur un morceau de plastique de la taille d’un timbre.
Selon un rapport de la société de conseil PricewaterhouseCoopers et comme le montre cette visualisation, l’univers numérique au complet, c’est à dire la somme de toutes les données accumulées dans le monde numérique, nécessitait 44 zettaoctets en 2020 (un zettaoctet = un million de millions de gigaoctets).
Mais la qualité des données est tout aussi importante que la quantité. Reprenons notre exemple précédent : un système qui a appris en utilisant des données météorologiques provenant de Suisse ne pourra pas prévoir le temps qu’il fera dans le désert du Sahara, quelle que soit la quantité de données historiques dont il dispose. Le système d’IA n’aurait jamais été exposé à des températures supérieures à 40° C, il est biaisé en faveur du climat des montagnes suisses, et ne généralisera donc pas avec des climats qu’il ne connaît pas. Et ce serait un problème même s’il y avait des dizaines d’années de données historiques à disposition.
De même, un sondage d’opinion réalisé à 15 heures un jeudi après-midi dans un parc n’est pas représentatif de la population globale d’un pays. Les personnes interrogées sont probablement des personnes âgées, des parents s’occupant de leurs enfants ou des personnes travaillant à domicile ou de nuit. Le sondage exclura presque entièrement la grande partie de la population qui occupe un emploi classique et donc se trouve au bureau à cette heure-là.
Étant donné l’importance des données et le rôle essentiel qu’elles jouent dans l’IA, nous couvrirons ces aspects plus en détail dans un prochain article : Des données si différentes. Mais maintenant, passons aux algorithmes et aux différentes tâches qu’ils apprennent.
Algorithmes et tâches d’apprentissage machine
Les algorithmes d’apprentissage machine, dont les fondements sont les statistiques et les mathématiques, sont la parfaite incarnation de comment l’apprentissage se déroule. Ces algorithmes, également appelés des modèles, analysent les données de manière agile afin d’y trouver les meilleures informations pour exécuter une tâche avec succès. Ce processus de recherche de la meilleure configuration (basée sur des signaux faibles trouvés dans les données) est ce que nous appelons “l’apprentissage”.
Notre article précédent, IA - Deux lettres aux multiples sens, expliquait comment les algorithmes modernes d’apprentissage machine diffèrent des algorithmes statiques, écrits par l’homme et basés sur des règles, notamment en ce qui concerne leur capacité à apprendre des données et des signaux qu’elles contiennent. Les algorithmes d’apprentissage machine modifient de manière itérative leur mode de fonctionnement afin d’améliorer leurs performances.
Ce processus est connu sous le nom de phase d’apprentissage, ou phase d’entraînement du modèle - et il est assez similaire à la façon dont les humains apprennent. Une bonne analogie de cet apprentissage est par exemple l’examen théorique pour le permis de conduire (le code de la route) pour lequel un étudiant doit, à chaque question, décider des actions à faire dans une série de scénarios de conduite réels.
Une façon de se préparer au test serait de répondre à de nombreux tests pratiques et de tirer parti de leurs solutions. En se confrontant à un large éventail de scénarios possibles, l’étudiant pourrait améliorer sa compréhension du code de la route et ainsi être mieux préparé pour le test final. Mais les questions du test final devraient alors être suffisamment différentes des tests utilisés pour réviser afin que l’apprentissage par cœur ne soit pas une stratégie viable.
L’entraînement d’un algorithme d’apprentissage automatique se déroule exactement de la même manière. Dans une première étape, le modèle apprend sur un ensemble de données appelé ensemble de formation, puis dans une deuxième étape, il est évalué séparément sur un autre ensemble de données, invisible, appelé ensemble de test. L’objectif final est que le modèle fonctionne aussi bien avec l’ensemble d’entraînement qu’avec l’ensemble de test. Cela garantit que le modèle n’a pas seulement mémorisé les détails de l’ensemble d’entraînement, mais qu’il peut également traiter des données nouvelles et jamais vues auparavant.
Bien sûr que les modèles s’entraînent ! C’est si facile… Eh bien non !
Alors comment ces modèles peuvent-ils apprendre et comment peuvent-ils être entraînés ? Prenez, par exemple, notre article précédent [lien vers “Coup d’œil derrière le rideau”], qui examinait comment prédire le poids des enfants en utilisant leur taille et d’autres caractéristiques. Dans cet article, notre modèle “simple” avait un paramètre interne (une valeur numérique), et le modèle avait appris la meilleure valeur de paramètre de 0,35 directement à partir des données. Pour certains modèles, il est possible de calculer directement ces meilleurs paramètres.
Une autre façon d’identifier le meilleur paramètre est de faire des essais à répétition et d’apporter des améliorations progressives. Vous pourriez partir d’une valeur de paramètre aléatoire (disons 0,1), ce qui, comme nous l’avons vu, conduirait à une performance assez médiocre du modèle. Mais si vous augmentez progressivement le paramètre, il finira par se rapprocher de la valeur optimale de 0,35 et donc le modèle s’améliorera pas à pas. Il est possible que l’on dépasse un peu la valeur espérée, mais comme cela réduirait la performance du modèle, il faudrait donc revenir sur nos pas pour atteindre la valeur optimale de 0,35.
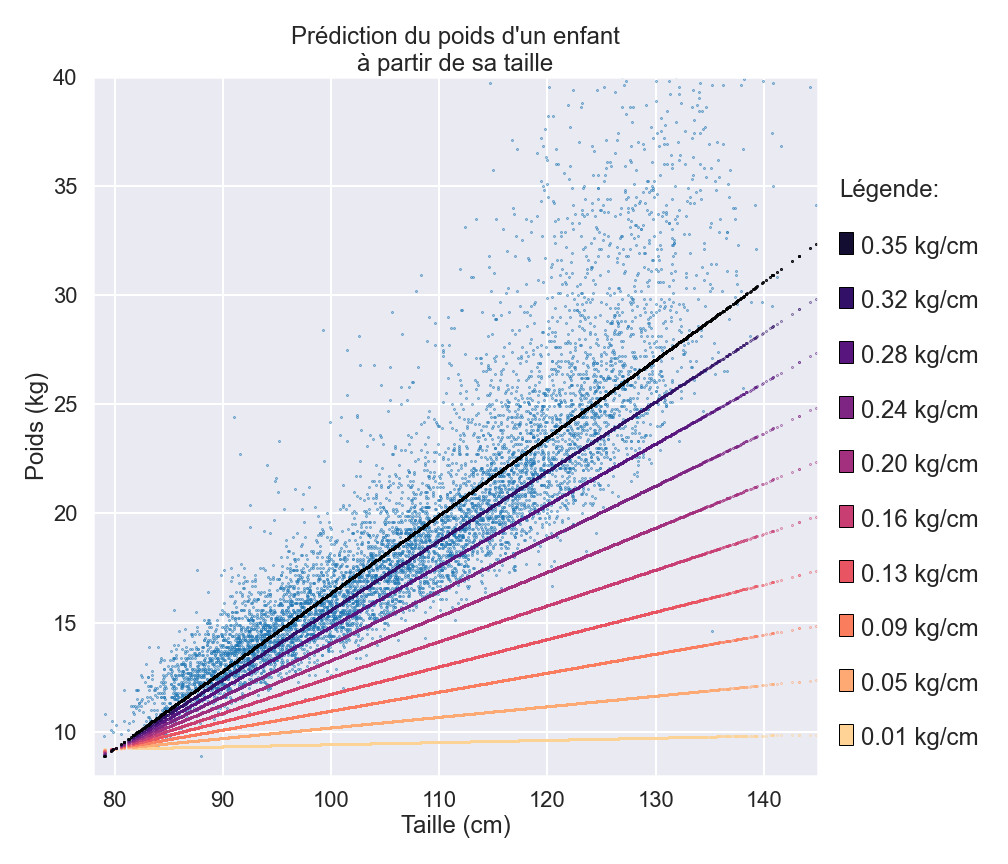
Mais comment savoir si le modèle s’améliore lorsque nous modifions un paramètre ? La réponse vient des données. Premièrement, elles nous fournissent la cible à atteindre (ici le poids réel des enfants) et deuxièmement, nous les utilisons pour faire des prévisions avec notre modèle provisoire. De cette façon, nous pouvons calculer de combien nos prédictions à un instant donné se trompent et donc évaluer si notre modèle s’est amélioré. Grâce à ce retour d’information, nous pouvons améliorer progressivement notre paramètre et, par conséquent, notre modèle apprend peu à peu à faire mieux. Nous, les humains, apprenons de la même manière lorsque nous répondons aux questions d’un quiz : suivant les réponses, nous apprenons et ajustons notre compréhension du sujet !
En réalité, cependant, les modèles sont beaucoup plus compliqués et ont beaucoup plus de paramètres. Mais l’idée fondamentale reste la même. Nous entraînons notre modèle en évaluant de manière répétée les prédictions actuelles (les dernières réponses) par rapport aux valeurs cible (les bonnes réponses)4 et nous apprenons comment ajuster les paramètres en mesurant justement nos erreurs afin de construire progressivement un modèle de plus en plus performant. En cours de route, les algorithmes d’apprentissage machine doivent donc effectuer des milliards de calculs impliquant les données d’entraînement afin de trouver le meilleur modèle.
Mais à mesure que les tâches deviennent plus complexes, les modèles nécessitent davantage de paramètres. Par conséquent, le nombre de combinaisons possibles de paramètres augmente en conséquence - ce qui peut donner l’impression de chercher une aiguille dans une botte de foin… de la taille de la Suisse ! Il se peut donc que nous ne trouvions pas les paramètres adéquats pour que notre modèle fonctionne suffisamment bien. La bonne nouvelle, c’est que certains modèles réussissent quand même. Pour vous donner une idée, un récent modèle très abouti appelé Generative Pre-trained Transformer 3 (GPT-3)5 peut effectuer de nombreuses tâches liées à la compréhension de textes, mais au prix faramineux de 175 milliards de paramètres !
Bien sûr, il y a plus d’une façon d’exploiter les données et il existe une variété de familles d’algorithmes d’apprentissage automatique. Celles-ci traitent les données de différentes manières et,6 à ce titre, ont des règles différentes pour l’utilisation des paramètres. Mais ce qu’elles ont toutes en commun, c’est cette capacité d’apprendre. Le choix d’une famille plutôt qu’une autre sera enfin une question de domaine d’expertise, de caractéristiques des données et, bien sûr, d’affinité avec une tâche en particulier.
Examinons un peu plus en détail trois familles différentes d’algorithmes d’apprentissage machine : l’approche basée sur les règles, l’approche par similarité et l’approche spécifique aux données.
Une approche fondée sur des règles
A votre avis, serait-il facile d’essayer de prédire si une personne va aller faire de la randonnée ce week-end ou plutôt aller au cinéma ? Sachant que les seules informations disponibles pour faire la prédiction sont quelques détails personnels de base, et une prévision météo ? Une approche d’apprentissage machine basée sur des règles chercherait des règles “si” et “sinon” dans les données. Les données pourraient nous montrer que si une personne a plus de 70 ans, elle est plus susceptible d’aller voir un film, quelle que soit la météo. Sinon, s’il fait beau, les gens sont plus susceptibles d’aller faire de la randonnée.
Approche par similarité
Une autre stratégie consiste à supposer que les personnes qui se ressemblent se comportent de la même manière. Si deux personnes ont la même taille, le même poids, le même âge et le même sexe (et ont des passe-temps et des emplois similaires), voudraient-elles passer leur temps libre à faire les mêmes activités ? C’est l’approche de la similarité, qui tente de regrouper les personnes considérées comme semblables entre elles.
Approche adaptée aux données
Le type de données utilisées par une tâche peut également influencer le choix de la famille modèle. Par exemple, travailler avec des images nécessite un algorithme qui peut tirer parti des informations propres aux images et certains modèles7 ont été spécifiquement développés à cet effet.
Puissance de calcul
Dans la section précédente, nous avons vu comment l’entraînement d’un algorithme d’apprentissage automatique peut coûter un milliard de calculs pour trouver les paramètres parfaits. La quantité de ressources nécessaires pour effectuer ces calculs peut être substantielle, et est devenue disponible grâce aux améliorations spectaculaires des capacités de stockage et de calcul au cours des dernières décennies.
Nous avons déjà abordé l’évolution du stockage, mais penchons-nous maintenant sur la puissance de calcul. La puissance des ordinateurs joue elle aussi un rôle crucial lorsqu’il s’agit de données et d’algorithmes. Le cerveau d’un ordinateur est son processeur (appelé CPU) qui a été inventé par le mathématicien, physicien, informaticien et ingénieur hongro-américain John von Neumann au milieu du XXe siècle. C’est un composant tout aussi important aujourd’hui qu’il l’était à l’époque. La capacité d’un CPU détermine le nombre de calculs et de traitement de données qui peuvent être effectués en une seconde, et donc le temps nécessaire pour terminer les calculs. Une façon courante d’augmenter cette capacité de nos jours est la parallélisation, lorsque plusieurs processeurs sont utilisés simultanément pour analyser les données.
Au cours des 50 dernières années, la capacité des processeurs individuels a doublé tous les deux ans environ - c’est ce qu’on appelle souvent la loi de Moore.8 Une tendance similaire peut être observée pour la quantité de calculs requise par les systèmes d’IA révolutionnaires jusqu’en 2012.
Toutefois, depuis lors, de nombreux ingénieurs et scientifiques ont utilisé des processeurs graphiques (GPU), initialement développés pour calculer le rendu des graphiques dans les jeux vidéo, afin d’accélérer considérablement les calculs requis par de nombreux algorithmes avancés d’apprentissage machine. Cette approche s’est depuis généralisée, et certaines entreprises développent même leurs propres processeurs personnalisés pour accélérer encore la phase d’apprentissage des modèles d’IA.
Cela signifie que les calculs nécessaires au développement de systèmes d’IA avancés doublent maintenant tous les trois ou quatre mois environ au lieu de tous les deux ans. En conséquence, nous observons une croissance plus de 50 fois plus rapide que la loi de Moore - une nouvelle ère de développement de l’IA a véritablement commencé.
Ainsi, en tenant compte du temps de calcul, estimons le coût du modèle GPT-3 (avec ses 175 milliards de paramètres) dont nous avons parlé précédemment. Le temps de calcul estimé serait de plus de 300 ans. Cela signifie que si vous deviez entraîner ce modèle sur un ordinateur personnel relativement puissant, il faudrait attendre environ 300 ans avant que l’entraînement ne donne un résultat satisfaisant.
Sur le plan financier, cela se traduit par un coût estimé à 4,6 millions de dollars. De nos jours, entraîner de modèles aussi puissants entraîne un coût de calcul et un coût financier élevés et laisse une empreinte carbone toujours croissante.9
Et pourtant, l’ordinateur utilisé par l’équipage d’Apollo 11 pour faire atterrir son vaisseau sur la lune en toute sécurité en 1969 avait une puissance de traitement inférieure à celle d’un téléphone portable moderne. Cela met bien en perspective la complexité de la tâche sur laquelle s’entraîne le modèle GPT-3 et les difficultés qu’ une machine peut avoir pour comprendre un texte.
Il serait tentant de penser que ces complexités rendent l’entraînement de nouveaux modèles trop difficile, mais des solutions sont maintenant à portée de main grâce au cloud. Au lieu de dépenser de l’argent dans des infrastructures coûteuses, les entreprises peuvent louer des grandes capacités de calcul dans des centres de données. Cette approche rend l’apprentissage machine accessible à de nombreuses entreprises. Mais cela étant dit, seules les organisations ou les personnes les plus riches peuvent entraîner aujourd’hui d’énormes modèles du niveau de complexité de GPT-3.
Expertise humaine
Mais pour que l’IA réussisse vraiment, elle a besoin d’un élément très important : l’expertise et l’encadrement humains.
Prenez, par exemple, un chef de projet dans un hôpital, qui a été chargé de développer un algorithme capable de prédire, à partir des rapports de radiologie, si un patient a contracté la COVID-19. L’objectif est donc de créer un algorithme qui pourrait aider à identifier rapidement les cas positifs parmi les milliers de ces rapports nouvellement disponibles. Voyons de plus près comment l’expertise humaine guide le développement du modèle d’IA.
La première tâche du chef de projet consisterait à collecter des données d’entraînement appropriées. Cela impliquerait de rencontrer les ingénieurs qui savent où les rapports de radiologie sont stockés dans l’entrepôt de données de l’hôpital et comment y accéder. Des discussions devraient très probablement avoir lieu avec les comités de protection de la vie privée pour s’assurer que seules des données dé-identifiées seront utilisées, sans aucune donnée personnelle.
La qualité et la diversité des données devront être évaluées et prises en compte. Y a-t-il des doublons, des erreurs ou des valeurs manquantes ? Les données sont-elles équilibrées en termes d’ âges, de sexes et d’états de santé de base ? Elles ne doivent pas contenir de biais indésirables qui pourraient faire pencher involontairement les prédictions vers une catégorie plutôt qu’une autre. Par exemple, si les patients représentés dans les données d’entraînement ont tous la même couleur de cheveux lorsqu’ils sont diagnostiqués comme ayant contracté la COVID-19, alors le modèle pourrait naïvement et faussement associer le fait d’avoir cette couleur de cheveux avec le fait de contracter la COVID-19.
Les rapports médicaux en eux-mêmes ne vous mèneront pas très loin - ils doivent être annotés pour en tirer le de la valeur. Le responsable du projet devra ainsi examiner ces rapports avec un groupe de radiologues et leur demander d’indiquer lesquels des patients concernés ont été rapportés positifs ou négatifs à la COVID-19. Pour éviter des erreurs d’annotation, plusieurs radiologues devraient examiner chaque rapport, valider et vérifier leur intégrité. Ils mettraient également en évidence toute information contradictoire ou tout désaccord et proposeraient des solutions. Ils joueraient également un rôle crucial pour déterminer, grâce à leur expertise, si l’on peut s’attendre à des prédictions de bonne qualité avec les données à disposition.
Une fois que les données d’entraînement ont été enrichies avec les annotations des radiologues, il est temps pour les scientifiques des données de prendre le relais. Leur travail consiste à préparer les données pour l’entraînement des algorithmes et la recherche des meilleurs paramètres, comme nous l’avons vu tout au long de cet article. Le défi est clair : l’algorithme d’apprentissage machine doit prédire le diagnostic de chaque patient potentiel COVID-19 aussi précisément que possible. Les spécialistes des données et les radiologues travailleront sur un objectif global, planifieront la manière d’évaluer les performances de l’algorithme et fixeront un objectif raisonnable. Ce faisant, ils devront prendre de nombreuses décisions. Par exemple, que se passe-t-il si le modèle prédit qu’un patient est positif à la COVID-19 alors qu’il est en fait en bonne santé, ou vice versa ? Qu’est-ce qu’un objectif raisonnable concernant la qualité des prédictions ? Avoir raison à 80% ? Ou 90 % ? Quel pourrait être l’impact ? Toutes ces questions soulignent l’importance du raisonnement et de l’intervention humaine : aucune machine ne peut résoudre ces questions, ce sont des questions fondamentalement humaines.
Maintenant que le modèle est entraîné, les experts du domaine, ainsi que les scientifiques chargés des données, examineront ses résultats et mettront au point des tests difficiles pour s’assurer que le modèle est stable et fiable avant son déploiement. Ils analyseront les défaillances du modèle afin d’identifier les faiblesses ou les possibilités d’amélioration, et finiront par entraîner à nouveau le modèle, encore et encore.
Toutes ces étapes mettent en évidence la quantité d’expertise humaine nécessaire au cours du processus - et ce n’est qu’une fois toutes ces étapes terminées qu’il est temps de déployer le nouveau modèle d’IA. La prise de décision humaine est ancrée dans les fondations de chaque modèle. Chaque utilisateur d’un modèle d’IA doit en être conscient.
C’est pourquoi les chercheurs en IA ont d’ailleurs récemment proposé un moyen de stocker et de partager ces informations sur des cartes d’identité de modèles10 (tout comme les cartes d’identité personnelles que nous utilisons). Ces cartes consistent en une liste rigoureuse de faits et de détails techniques concernant le modèle : les données utilisées pour l’entraîner, la manière dont il a été évalué, l’usage auquel il est destiné ainsi que des considérations éthiques et des mises en garde connues. Un exemple de carte d’identité de modèle de détection des visages, comprenant la liste des caractéristiques et des descripteurs du modèle, peut être trouvé ici.
Ces cartes tentent d’ouvrir la boîte noire qui est associée à l’IA. En fournissant des évaluations quantitatives et de la transparence, elles mettent en évidence les lacunes, suggèrent des améliorations potentielles et facilitent le discours sur les systèmes d’IA et leur utilisation. Et bien sûr, ces cartes et les modèles qui leur sont associés évolueront au fil du temps, à mesure que les utilisateurs identifieront de nouveaux biais, de nouvelles faiblesses ou des nouveaux cas d’usage inédits du modèle.
Dans l’ensemble, il est important de se rappeler qu’un juste mélange de données, d’algorithmes, de puissance de calcul et d’expertise humaine est crucial pour créer un système d’IA réussi.
-
La ressource la plus précieuse du monde : Les données et les nouvelles règles de la concurrence, The Economist. Image Article 6 mai 2017. ↩
-
Un numéro qui doit être changé tous les quelques mois. ↩
-
Il existe des tâches pour lesquelles le système d’IA ne reçoit pas de solution ou de cible par rapport à laquelle il peut évaluer ses performances, par exemple lorsqu’il regroupe toutes les photos de personnes qui se ressemblent. Mais nous en discuterons dans un sujet plus avancé. ↩
-
Régressions linéaires, arbres de décision, machines à vecteurs de support, forêts d’arbres décisionnels, réseaux de neurones… ↩
-
Ces modèles sont connus sous le nom de réseau neuronal convolutif. ↩
-
La loi de Moore est une observation nommée d’après Gordon Moore, cofondateur d’Intel, qui a suggéré en 1965 que le nombre de transistors dans un circuit intégré dense double environ tous les deux ans. Comme sa conjecture s’est avérée valide, on parle maintenant de “loi”. ↩
-
[L’entraînement d’un seul modèle d’IA peut émettre autant de carbone que cinq voitures au cours de leur vie] (https://www.technologyreview.com/2019/06/06/239031/training-a-single-ai-model-can-emit-as-much-carbon-as-five-cars-in-their-lifetimes/). ↩
-
Introduit pour la première fois dans Fiches de modèle pour les rapports de modèle (Margaret Mitchell et. al., 2019). ↩
{kind=link}