In den vorangegangenen Artikeln haben wir erläutert, was man als KI bezeichnen kann und was nicht. Wir haben untersucht, wie Algorithmen unser tägliches Leben beeinflussen, und haben den Lernprozess von KI mit seinem menschlichen Pendant verglichen.
Hie nehmen wir uns die Zeit, die grundlegenden Bausteine der KI zu betrachten. Bisher haben wir uns angeschaut, was KI-Technologie bereits leisten kann und auf welche Weise wir diese Errungenschaften bewerten können. Aber was ist eigentlich nötig, damit KI richtig funktionieren kann?
Im Wesentlichen gibt es vier Grundbausteine, die das Rückgrat der KI bilden:
- Daten
- Algorithmen und Aufgaben des maschinelles Lernens
- Rechenleistung
- Menschliches Fachwissen
Oder in einem einzigen Satz ausgedrückt: “Menschen trainieren maschinelle Lernalgorithmen mit Hilfe von Daten und Computern mit hoher Rechenleistung und mit diesen dann eine bestimmte Aufgabe zu lösen”. Das Ziel der folgenden Abschnitte ist es, sicherzustellen, dass Sie diesen Satz vollständig verstehen!
Die jüngsten Erfolge in der KI-Technologie lassen sich auf mehrere Phänomene zurückführen, die eng mit diesen vier Grundbausteinen verbunden sind: das Aufkommen des Internets, soziale Netzwerke, technologische Durchbrüche und bedeutende theoretische Fortschritte in der Wissenschaft. Um ein wirkliches Verständnis für diese Bausteine zu bekommen, muss man folgendes bedenken: Wie arbeiten sie jetzt zusammen? Warum konnten sie das nicht schon vorher? Und was sonst ihren heutigen Erfolg ermöglicht?
Daten
Heutzutage taucht das Wort Daten in vielen Stellenausschreibungen auf virtuellen Jobbörsen auf. In der Tat arbeiten viele Menschen heute fast ausschliesslich an datenbezogenen Aufgaben. Sie sammeln Daten, transformieren sie, visualisieren sie, speichern sie und verkaufen sie. Man sagt, dass Daten der wertvollste Rohstoff der Welt geworden sind 1, und einer der Gründe sind KI-Systeme, die viele Daten zum Lernen brauchen.
Daten können von Menschen, Sensoren, Maschinen und Apps erfasst werden. Doch wie sehen sie eigentlich aus? Nun, jede Beobachtung, die wir machen, enthält Informationen. Sobald diese aufgezeichnet werden, entweder auf einem Stück Papier, einer Festplatte oder einem Foto, werden daraus Daten. Daten sind also die Aufzeichnung von Informationen in quantitativer und qualitativer Form, die zur späteren Verwendung gespeichert werden. Daten speichern also Informationen in quantitativer und qualitativer Form zur späteren Verwendung. In der Tat werden die Begriffe “Information” und “Daten” oft gleichgesetzt.
Damit Menschen oder KI-Systeme aus Daten lernen können, müssen diese repräsentativ und vollständig sein - es ist ein qualitativer und quantitativer Ansatz erforderlich. Ist dies nicht der Fall, wird der Lernprozess höchstwahrscheinlich beeinträchtigt und führt zu fehlerhaften, tendenziösen und verzerrten Ergebnissen.
Ein KI-System, das auf Wettervorhersage trainiert wurde, wird z. B. nicht in der Lage sein, genaue Prognosen für eine kalte Winterwoche zu machen, wenn es nur mit Daten aus den Sommermonaten gefüttert wurde. Es hat im Lernprozess noch nie einen kompletten Jahreszeitenzyklus kennengelernt, daher würde es sich schwer tun, Datenmuster zu finden, die sich auf das ganze Jahr beziehen. Allerdings wäre ein einzelnes Jahr mit einem ungewöhnlich nassen Sommer auch nicht repräsentativ. Idealerweise würden wir also vollständige Datensätze aus mehreren Jahren haben wollen.
Tatsächlich können selbst einfache Algorithmen komplexe Aufgaben mit Leichtigkeit lösen, wenn sie nur genügend Daten zum Lernen erhalten - erhöhen wir die Datenmenge und können wir eine Leistungssteigerung sehen. Das zeigt auf beeindruckende Weise, dass für das Trainieren eines KI-Systems die Daten oft wichtiger sind als die Komplexität der Algorithmen. Dies wird oft als “Die unverhältnismässige Effektivität von Daten” bezeichnet2) - und es war auch die Geburtsstunde des Begriffs “Big Data”. Diese Effektivität ist in den letzten Jahren immer deutlicher geworden, da durch den Vormarsch des Internets immer mehr Daten zur Verfügung stehen. Jetzt teilen Milliarden von Menschen jeden Tag Informationen und greifen darauf zu.
Aber auch bei der Speicherung von Daten hat sich in den letzten Jahren so einiges getan. Um im Jahre 1956 fünf Megabyte zu speichern - etwa die Grösse eines sechsminütigen Liedes - brauchte man einen IBM RAMAC 305 Computer. Dieser Koloss wog über eine Tonne und in dieser Abbildung können Sie sehen wie gross er war.
{kind=link}
In den 1980er Jahren konnte man die gleiche Menge an Informationen anfangs dreissig, später nur noch fünf, 8-Zoll-Disketten speichern, die zusammen ein paar hundert Gramm wogen. Unnötig zu erwähnen, dass die heutigen Standard-SD-Speicherkarten zwei Gramm wiegen und mehr als 128 Gigabyte (über 25.000 Songs)3 auf einem Stück Plastik von der Grösse einer Briefmarke speichern können. Laut einem Bericht des Beratungsunternehmens PricewaterhouseCoopers und wie in dieser Infografik zu sehen, benötigt das akkumulierte digitale Datenuniversum im Jahr 2020 44 Zettabyte (ein Zettabyte = eine Million Millionen Gigabyte).
Aber die Qualität der Daten ist genauso wichtig wie die Quantität. Nehmen wir unser vorheriges Beispiel - ein System, das mit Wetterdaten aus der Schweiz trainiert wurde. Unabhängig von der Menge der historischen Aufzeichnungen, die ihm zur Verfügung stehen wird es nicht in der Lage sein, das Wetter in der Sahara vorherzusagen. Das KI-System wäre nie Temperaturen über 40° C ausgesetzt gewesen, es ist voreingenommen gegenüber dem Schweizer Gebirgsklima und kann seine Prognosen nicht auf Klimazonen ausweiten, die es nicht kennt. Und das wäre selbst dann ein Problem, wenn jahrzehntelange historische Aufzeichnungen verfügbar wären.
In ähnlicher Weise ist eine Meinungsumfrage, die um 15 Uhr an einem Donnerstagnachmittag in einem Park durchgeführt wird, nicht repräsentativ für die Gesamtbevölkerung eines Landes. Bei den befragten Personen handelt es sich wahrscheinlich um Senioren, Eltern, die sich um ihre Kinder kümmern, oder Menschen, die von zu Hause aus oder in Nachtschichten arbeiten. Die Umfrage wird den grossen Teil der Bevölkerung, der eine typische 40-Stundenwoche absolviert, fast vollständig ausschliessen.
Angesichts der Bedeutung von Daten und der integralen Rolle, die sie bei der KI spielen, werden wir diese Aspekte in einem späteren Artikel ausführlicher behandeln: Daten in verschiedenen Formen. Jetzt aber lassen Sie uns einen Blick auf Algorithmen und Aufgaben werfen.
Algorithmen und Aufgaben des maschinelles Lernens
Algorithmen für maschinelles Lernen, deren Grundlagen in der Statistik und Mathematik liegen, sind die Blaupause dafür, wie das Lernen stattfindet. Diese Algorithmen, die auch als Modelle bezeichnet werden, analysieren die Daten auf eine agile Art und Weise. Ihr Ziel ist es, die beste Methode zur erfolgreichen Ausführung ihrer Aufgabe zu finden. Diesen Prozess des Findens der besten Einstellungen (basierend auf den in den Daten gefundenen Mustern) nennen wir “Lernen”.
In unserem früheren Artikel KI - Mehr als ‘nur’ ein Programm wurde erörtert, wie sich moderne Lernalgorithmen von den statischen, regelbasierten, von Menschen geschriebenen Algorithmen unterscheiden. Wir haben im Besonderen ihre Fähigkeit, aus Daten und den darin enthaltenen Mustern zu lernen, hervorgehoben. Algorithmen für maschinelles Lernen ändern iterativ ihre Arbeitsweise, um ihre Leistung zu verbessern.
Dieser Prozess wird als Lernphase oder Trainingsphase des Modells bezeichnet - und er ist der Art und Weise, wie Menschen lernen, recht ähnlich. Eine gute Analogie ist eine Theorieprüfung für einen Führerschein, bei der eine Fahrschülerin entscheiden muss, welche Handlungen sie in einer Reihe von realen Verkehrsszenarien ausführen soll.
Eine Möglichkeit, sich auf die Prüfung vorzubereiten, wäre, viele Übungstests zu machen und aus den Auswertungen der eigenen Antworten zu lernen. Indem die Fahrschülerin einer Vielzahl möglicher Szenarien ausgesetzt wird, könnte sie ihr Verständnis der Verkehrsregeln verbessern und so besser auf die abschliessende Prüfung vorbereitet sein. Aber damit stures Auswendiglernen nicht zum Erfolg führen kann, müssen sich die Fragen des Abschlusstests ausreichend von den Übungsaufgaben unterscheiden.
Das Trainieren eines maschinellen Lernalgorithmus geschieht auf genau dieselbe Weise. In einem ersten Schritt wird das Modell mit so genannten Trainingsdaten angelernt, bevor es in einem zweiten Schritt separat auf einem anderen, unbekannten Datensatz, den so genannten Testdaten, ausgewertet wird.
Das ultimative Ziel ist, dass das Modell mit den Trainingsdaten genauso gut abschneidet wie mit den Testdaten. Dadurch wird sichergestellt, dass das Modell sich nicht nur die Details der Trainingsdaten gemerkt hat - es muss beweisen, dass es mit neuen, noch unbekannten Daten genauso gut umgehen kann.
Warum das Training von Modellen nicht so einfach ist
Wie können Modelle letzten Endes lernen? Und wie können sie trainiert werden? Nehmen wir als Beispiel unseren vorhergehenden Artikel Ein Blick hinter die Kulissen, in dem es darum ging, wie man das Gewicht von Kindern anhand ihrer Grösse und anderer Merkmale vorhersagen kann.
In dieser Geschichte hatte unser einfaches Modell einen internen Parameter (einen numerischen Wert). Das Modell hatte den besten Parameterwert von 0,35 direkt aus den Daten gelernt. Für einige Modelle gibt es diesen direkten Ansatz, die besten Parameter zu berechnen.
Eine andere Möglichkeit, den besten Parameter zu ermitteln, ist durch wiederholtes Feedback und durch schrittweise Verbesserungen. Sie könnten mit einem zufälligen Parameterwert - sagen wir 0,1 - beginnen. Wie wir bereits gesehen haben, führt dieser Wert zu einer ziemlich schlechten Leistung des Modells. Wenn wir den Parameter jedoch schrittweise erhöhen, würde er sich schliesslich dem optimalen Wert von 0,35 annähern und somit das Modell Schritt für Schritt verbessern. Es besteht die Möglichkeit, anfangs ein wenig über das Ziel hinauszuschiessen. Das würde die Leistung des Modells wieder verringern. Doch in dem Fall würden wir auf Grund dieser Beobachtung unsere Schritte langsam zurückverfolgen, und so irgendwann den optimalen Wert von 0,35 erreichen.
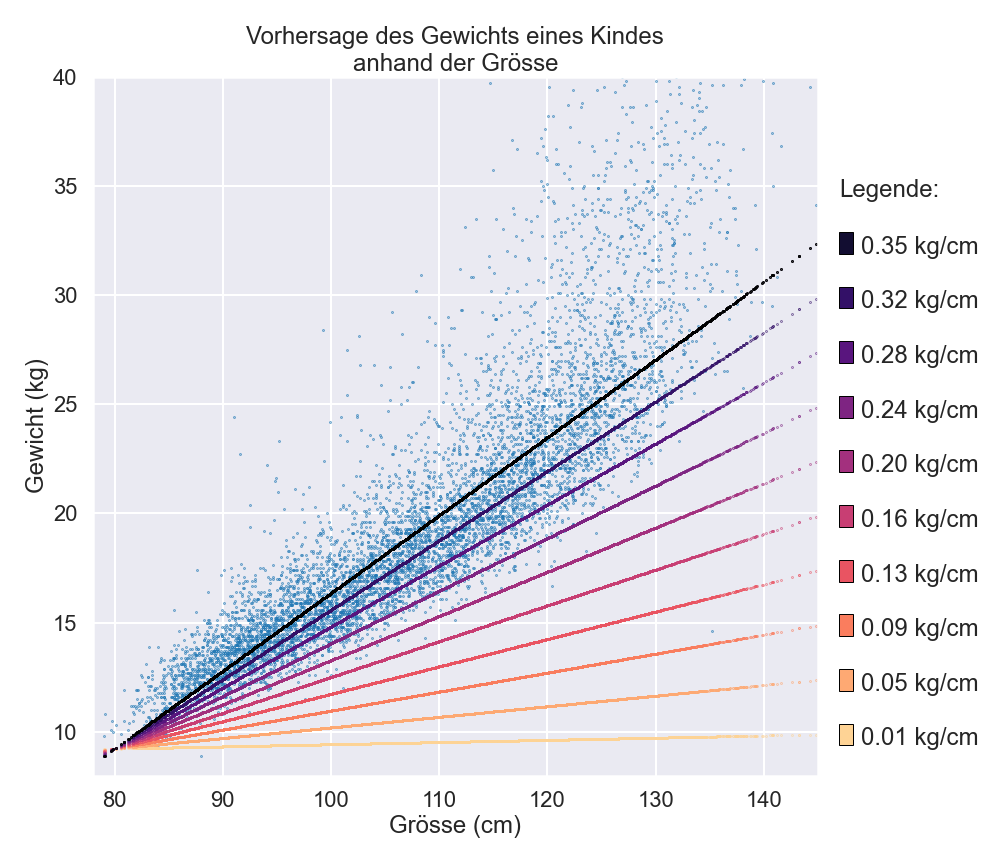
Aber wie können wir überhaupt feststellen, ob sich das Modell verbessert, wenn wir den Parameter ändern? Die Antwort finden wir mit Hilfe der Daten.
Erstens geben sie unser Ziel vor (das wahre Gewicht der Kinder), und zweitens verwenden wir die Daten, um mit unserem vorläufigen Modell Vorhersagen zu machen. Auf diese Weise können wir berechnen, um wieviel unsere Vorhersagen vom Ziel abweichen und somit beurteilen, ob sich unser Modell verbessert hat.
Dank dieser Rückmeldung können wir unsere Parameter schrittweise verbessern - und dadurch lernt unser Modell allmählich, besser zu werden. Wir Menschen durchlaufen den gleichen Prozess, wenn wir zum Beispiel mit einem Ball auf ein Ziel werfen; wir passen unsere Wurfbewegung gemäss den letzten Versuchen an.
In der Realität sind die Modelle viel komplizierter und haben viel mehr interne Parameter. Aber der Grundgedanke bleibt derselbe: Wir trainieren unser Modell, indem wir unsere aktuellen Vorhersagen (unsere letzten Antworten) wiederholt mit unserer Zielvorgabe (die richtigen Antworten4) vergleichen. Wir lernen aus unseren Fehlern, wie wir die Parameter anpassen können, um nach und nach ein besseres Modell zu erstellen. Auf dem Weg dorthin könnten die KI-algorithmen Milliarden von Berechnungen mit dem Datensatz durchführen, bevor sie das beste Modell finden.
Aber je komplexer die Aufgaben werden, desto mehr Parameter benötigen die Modelle. Damit steigt die Anzahl der möglichen Kombinationen entsprechend rasant an - was dazu führen kann, dass man eine Nadel in einem Heuhaufen von der Grösse der Schweiz sucht. Es kann sein, dass wir am Ende keine geeigneten Parameter finden, mit denen unser Modell ausreichend gut funktioniert.
Die gute Nachricht ist, dass einige Modelle dennoch erfolgreich sind. Um Ihnen eine Vorstellung davon zu geben, ein aktuelles, sehr erfolgreiches Modell - genannt Generative Pre-trained Transformer 3 (GPT-3)5 - kann viele anspruchsvolle Aufgaben im Bereich des maschinellen Textverständnisses durchführen. Allerdings braucht es dazu schwindelerregende 175 Milliarden Parametern!
Doch kommen wir zurück zu der Frage wie Algorithmen aus Daten lernen können. Wie so oft gibt es mehr als einen Weg. Es gibt eine grosse Bandbreite an Familien von Lernalgorithmen, die jede Daten auf ihre eigene Art und Weise behandeln6, und somit auch unterschiedliche Regeln für die Verwendung von Parametern haben. Aber sie alle besitzen die Fähigkeit aus Daten zu lernen. Die Wahl einer Familie gegenüber einer anderen ist eine Frage von Fachwissen, der Eigenschaften der Daten und natürlich der jeweiligen Aufgabe.
Lassen Sie uns drei verschiedene Familien von Algorithmen des maschinellen Lernens etwas näher betrachten - den regelbasierten Ansatz, den Ähnlichkeitsansatz und den datenspezifischen Ansatz.
Regelbasierter Ansatz
Was glauben Sie, wie einfach es wäre, vorherzusagen, ob eine Person wandern oder ins Kino gehen wird? Was ist, wenn die einzigen Informationen, die für die Vorhersage zur Verfügung stehen, einige grundlegende persönliche Details und eine Wettervorhersage sind?
Ein regelbasierter Ansatz des maschinellen Lernens würde in den Daten nach “Wenn-dann-es” Regeln suchen. Die Daten könnten uns zeigen, dass eine Person, die über 70 Jahre alt ist, mit höherer Wahrscheinlichkeit in einen Film geht, unabhängig vom Wetter. Andernfalls, wenn es sonnig ist, dann werden die Leute eher wandern gehen.
Ähnlichkeits-Ansatz
Eine andere Strategie ist die Annahme, dass Menschen, die sich ähnlich sind, sich auch ähnlich verhalten. Wenn zwei Personen sich in Grösse, Gewicht, Alter und Geschlecht ähneln und ähnliche Hobbys und Berufe ausüben, würden sie dann ihre Freizeit dieselben Aktivitäten ausüben wollen?
Dies ist der Ähnlichkeits-Ansatz, der versucht, diejenigen miteinander zu gruppieren, die sich ähnlich sind.
Datenspezifischer Ansatz
Die Art der Daten, die von einer Aufgabe verwendet werden, kann ebenfalls die Wahl der Modellfamilie beeinflussen. Zum Beispiel erfordert die Arbeit mit Bildern einen Algorithmus, der die räumliche Beziehung einzelner Pixel bei der Suche nach besonderen Mustern nutzen kann, und einige Modelle7 wurden speziell dafür entwickelt.
Rechenleistung
Im vorigen Abschnitt haben wir beschrieben, wie das Training eines KI-Algorithmus mit einer Unmenge von Berechnungen verbunden sein kann, um die perfekten Parameter zu finden. Die Menge an Ressourcen, die für die Durchführung dieser Berechnungen benötigt wird, kann beträchtlich sein. Doch sie stehen dank dramatischer Verbesserungen bei Speicher- und Rechenkapazitäten in den letzten Jahrzehnten zur Verfügung.
Wir haben uns bereits damit befasst, wie sich die Speicherung entwickelt hat, also lassen Sie uns jetzt einen Blick auf die Rechenleistung werfen.
Wenn es um Daten und KI-Algorithmen geht, spielt die Rechenleistung von Computern eine entscheidende Rolle. Das Gehirn eines Computers ist seine CPU, die Central Processing Unit, die Mitte des 20. Jahrhunderts von dem ungarisch-amerikanischen Mathematiker, Physiker, Informatiker und Ingenieur John von Neumann erfunden wurde. Und sie ist heute eine ebenso wichtige Komponente wie damals.
Die Kapazität einer CPU bestimmt, wie viele Berechnungen und wie viele Datenverarbeitungsschritte innerhalb einer Sekunde durchgeführt werden können - und damit wie lange die Berechnungen dauern. Ein heutzutage beliebter Weg, diese Kapazität zu erhöhen, ist die Parallelisierung, bei der mehrere CPUs gleichzeitig zur Analyse der Daten verwendet werden.
In den letzten 50 Jahren hat sich die Kapazität einzelner CPUs etwa alle zwei Jahre verdoppelt - dies wird oft als Mooresche Gesetz (Moore’s Law8) bezeichnet. Ein analoger Trend kann für die Menge an Berechnungen beobachtet werden, die von bahnbrechenden KI-Systemen bis etwa 2012 benötigt wurden.
Seitdem haben jedoch viele Ingenieure und Datenwissenschaftler grafische Verarbeitungseinheiten (vom Englischen graphical processing units oder kurz GPUs) eingesetzt. Ursprünglich waren sie für das Erstellen von hochwertigen Grafiken in Videospielen entwickelt worden, konnten aber exzellent genutzt werden, um die für viele fortschrittliche KI-Algorithmen erforderlichen Berechnungen erheblich zu beschleunigen. Dieser Ansatz ist inzwischen zum Mainstream geworden, und einige Unternehmen entwickeln sogar ihre eigenen benutzerdefinierten Einheiten, um das Trainieren von KI-Modellen weiter zu verbessern und zu beschleunigen.
Das bedeutet nebenbei, dass sich die für die Entwicklung fortschrittlicher KI-Systeme zur Verfügung stehenden Rechenleistungen, sich jetzt etwa alle drei bis vier Monate verdoppeln, statt zuvor alle zwei Jahre. Als Ergebnis sehen wir ein Wachstum, das mehr als 50 Mal schneller ist als das Mooresche Gesetz. Eine neue Ära der Entwicklung von KI-Systemen ist angebrochen.
Lassen Sie uns also unter Berücksichtigung der Rechenzeit die Kosten für das bereits erwähnte GPT-3-Modell (mit seinen 175 Milliarden Parametern) abschätzen. Die geschätzte Rechenzeit würde mehr als 300 Jahre betragen - mit anderen Worten, wenn Sie dieses Modell auf einem leistungsstarken Privatrechner trainieren würden, müssten sie ungefähr 300 Jahre warten, bis der Lernprozess tatsächlich ein zufriedenstellendes Ergebnis liefert.
Finanziell ergibt das geschätzte Kosten von 4,6 Millionen Dollar. Das Training solch leistungsfähiger Modelle ist heutzutage mit einem hohen rechnerischen und finanziellen Aufwand verbunden und hinterlässt einen immer grösser werdenden ökologischen Fussabdruck9.
Im Gegensatz dazu hatte der Computer, mit dem die Apollo-11-Crew 1969 sicher auf dem Mond landete, weniger Rechenleistung als ein modernes Mobiltelefon. Dies relativiert, wie komplex der Lernprozess des GPT-3-Modells ist und wie schwierig es für eine Maschine bleibt, Text zu verstehen.
Es wäre einfach zu denken, dass diese Komplexität die Entwicklung neuer Modelle zu einer zu grossen Herausforderung macht, aber dank der “Cloud” ist jetzt Hilfe zur Hand. Anstatt teure Infrastruktur zu kaufen, können Unternehmen diese stattdessen in den grossen Rechenzentren anmieten. Dieser Ansatz macht maschinelles Lernen für viele Unternehmen zugänglich. Aber es sind weiterhin nur die reichsten Organisationen und Einzelpersonen, die sich heute das Training riesiger Modelle, wie dem GPT-3, leisten können.
Menschliches Fachwissen
Damit KI wirklich erfolgreich sein kann, braucht sie jedoch ein sehr wichtiges Element: menschliches Know-How und Anleitung.
Nehmen Sie zum Beispiel einen Projektmanager in einem Krankenhaus, der die Aufgabe hat, einen Algorithmus zu entwickeln, der anhand von radiologischen Berichten vorhersagen kann, ob ein Patient mit COVID-19 infiziert ist. Das Ziel ist es, einen Algorithmus zu erstellen, der helfen könnte, positive Fälle innerhalb von Tausenden von neu verfügbaren schriftlichen Berichten schnell zu identifizieren. Lassen Sie uns einen genaueren Blick darauf werfen, wie menschliche Expertise die Entwicklung des KI-Modells leitet.
Die erste Aufgabe für den Projektleiter wäre es, die entsprechenden Trainingsdaten zu sammeln. Dazu muss er sich mit den Ingenieuren treffen, die wissen, ob und wo die radiologischen Berichte digital gespeichert wurden und wie man Zugriff auf sie erhält. Höchstwahrscheinlich müssten Gespräche mit Datenschutzbeauftragten geführt werden, um sicherzustellen, dass nur anonymisierte Daten verwendet werden, im Gegensatz zu personenbezogenen Daten.
Die Datenqualität und -vielfalt müssen berücksichtigt werden. Gibt es Duplikate, Fehler oder fehlende Werte? Sind die Daten gleichmässig über Alter, Geschlecht und gesundheitliche Vorerkrankungen verteilt? Sie sollten auch frei von unerwünschten Verzerrungen sein, die Vorhersagen unbeabsichtigt in Richtung einer Kategorie verschieben könnten. Wenn die Trainingsdaten z. B. in einer kleinen Studentenstadt erhoben wurden und dadurch die Mehrheit derer Patienten, bei denen das Coronavirus diagnostiziert wird, Studenten sind, dann könnte das Modell naiv und fälschlicherweise diese Altersgruppe mit der Erkrankung an COVID-19 assoziieren.
Medizinische Berichte allein bringen Sie nicht sehr weit - die Berichte müssen mit Diagnosen versehen werden, um das Beste aus den jeweiligen Berichten herauszuholen. Der Projektleiter müsste diese Berichte mit einer Gruppe von Spezialisten durchgehen, die analysieren, welche Patienten positiv oder negativ auf das Virus getestet wurden.
Um Fehler bei der Kommentierung zu vermeiden, müssten die Spezialisten alle Berichte auf ihre Integrität hin überprüfen. Sie müssten dabei alle widersprüchlichen Informationen oder Unstimmigkeiten hervorheben und entsprechende Lösungen für diese anbieten. Und sie würden eine entscheidende Rolle spielen bei der Erörterung, ob genaue Vorhersagen mit den vorliegenden Daten überhaupt machbar sind.
Sobald diese Trainingsdaten mit den Annotationen der Radiologen kombiniert wurden, ist es an der Zeit, dass Datenwissenschaftlern die Arbeit übernehmen. Ihre Aufgabe ist es, die Daten für das Training der KI-Algorithmen vorzubereiten und die besten Parameter zu finden, wie bereits in diesem Artikel beschrieben. Die Herausforderung ist klar: Der maschinelle Lernalgorithmus soll die Diagnose für jeden potenziellen COVID-19-Patienten so genau wie möglich vorhersagen. Datenwissenschaftler und Radiologen erarbeiten dazu ein übergeordnetes Ziel, planen, wie die Leistung des Algorithmus zu bewerten ist, und legen ein angestrebtes Qualitätsniveau fest. Dabei gibt es viele Entscheidungen zu treffen. Was passiert, wenn das Modell z. B. vorhersagt, dass ein Patient COVID-19 hat, obwohl er eigentlich gesund ist, oder andersherum? Was ist ein vernünftiges Ziel für die Qualität der Vorhersagen? In 80% der Fälle richtig zu liegen? Oder in 90 %? Was könnte die Auswirkung sein? Dies unterstreicht die Bedeutung menschlichen Urteilsvermögens und Eingreifens: Keine Maschine kann diese Frage lösen, dies ist eine grundsätzlich menschliche Frage.
Nachdem das Modell trainiert wurde, werden Fachleute gemeinsam mit Datenwissenschaftlern seine Ergebnisse in anspruchsvollen Tests genau überprüfen. Dabei werden die fehlerhaften Vorhersagen des Modells im Detail auf Schwachstellen analysiert und Verbesserungsmöglichkeiten ermittelt. Mit Hilfe dieser wird das Modell immer wieder überarbeitet, neu trainiert und analysiert, und so schrittweise verbessert. Ziel ist es sicherzustellen, dass das Modell hochwertig, zuverlässig und stabil ist, bevor es zum Einsatz kommt. All diese Zwischenschritte verdeutlichen, wie viel menschliche Expertise während des gesamten Projekts benötigt wird - und erst wenn sie abgeschlossen sind, ist es an der Zeit, das neue KI-Modell einzusetzen. Die menschlichen Entscheidungen bilden das Gerüst hinter jedem Modell. Jeder Anwender eines Modells muss sich dessen bewusst sein. Aus diesem Grund haben KI-Forscher kürzlich eine Möglichkeit vorgeschlagen, diese Informationen auf Modellkarten10 festzuhalten und zugänglich zu machen (eine Art Personalausweis der KI-Modelle). Diese Karten bestehen aus einer präzisen Liste von Fakten und technischen Details über das Modell: die Daten, mit denen es trainiert wurde, wie es ausgewertet wurde, seine beabsichtigte Verwendung sowie ethische Überlegungen und bekannte Vorbehalte. Ein Beispiel für eine Karte eines Gesichtserkennungsmodells, einschliesslich einer Liste von Modelleigenschaften und Deskriptoren, finden Sie hier.
Diese Karten versuchen, die Blackbox zu öffnen, die mit KI verbunden ist. Durch die Bereitstellung quantitativer Auswertungen und Transparenz weisen sie auf Mängel hin, schlagen mögliche Verbesserungen vor und erleichtern den Diskurs über KI-Systeme und deren Einsatz. Und natürlich werden sich diese Karten und die dazugehörigen Modelle im Laufe der Zeit weiterentwickeln, wenn das Feedback der Benutzer weitere Verzerrungen, Schwächen oder erfolgreiche Anwendungen des Modells aufzeigt.
Alles in allem ist es wichtig, sich daran zu erinnern, dass ein ausbalanciertes und harmonisches Zusammenspiel von Daten, maschinellen Lernalgorithmen, Rechenleistung und menschlicher Expertise entscheidend ist, um ein erfolgreiches KI-System zu schaffen.
-
The world’s most valuable resource: Data and the new rules of competition, The Economist. Picture Article May, 6th 2017. ↩
-
Der Ausdruck stammt vom Titel eines englischensprachigen Forschungspapiers in dem diese Beobachtungen gemacht wurden: “The unreasonable effectiveness of data” Paper ↩
-
Eine Zahl die alle 6 Monate angepasst werden muss. ↩
-
Es gibt Aufgaben, bei denen das KI-System keine Lösung oder Zielvorgabe erhält, mit deren Hilfe es seine Leistung bewerten kann, z. B. wenn es alle Fotos von Personen, die gleich aussehen, zusammenstellt. Aber wir werden dies in einem späteren Thema besprechen. ↩
-
Lineare Regressionen, Entscheidungsbäume, Support Vector Machines, Random Forests, Neuronale Netze… ↩
-
Diese Modelle werden als Convolutional Neural Networks oder Faltungsneuronale Netze bezeichnet. ↩
-
Das Mooresche Gesetz ist eine Beobachtung, die nach Gordon Moore, dem Mitbegründer von Intel, benannt ist. Er vermutete 1965, dass sich die Anzahl der Transistoren in einem dichten integrierten Schaltkreis etwa alle zwei Jahre verdoppelt. Da sich seine Vermutung als zutreffend herausstellte, wird sie heute als “Gesetz” bezeichnet. ↩
-
Die Lernphase eines einzigen KI-Modells kann so viel Kohlendioxid ausstossen wie fünf Autos in ihrer Laufzeit. Artikel in Englisch ↩
-
Erstmals erwähnt im englischsprachigen Artikel Model Cards for Model Reporting (Margaret Mitchell et. al., 2019). ↩
{kind=link}