The road to true artificial intelligence is long and winding. Experts believe that we are still in the very early stages of this journey – and so far we’ve only taken the first few steps. But just like small children learning to walk, these first steps can already be mightily impactful, and soon the distances are completed in long strides.
The technology that enabled us to take these first steps and transform the dream of artificial intelligence (AI) into something real is called machine learning. As we learned in a previous article, machine learning is a subset of AI which uses statistical methods to learn from data. If you’ve read anything about the capabilities of a new AI technology in the last few decades, the chances are what they actually meant is machine learning.
In the article Building Blocks of AI, we learned about the four pillars that are needed for today’s AI applications: machine learning algorithms, (big) data, computing power and human expertise. Therefore understanding what machine learning is really all about will allow you to better understand what AI is – and what it might be able to do in the future…
What is machine learning?
Each of us knows what learning is1 – after all, it’s human nature. We do it every single day, as it helps us to adapt and survive in the world. But how exactly does it happen? The Greek philosopher Aristotle explained it nicely when he wrote: “For the things we have to learn before we can do them, we learn by doing them.”
In other words, if we want to learn something, we need to do and experience it. We need to observe the consequences of our (or somebody else’s) actions, whether they are positive or negative. This procedure allows us to better understand how things are connected and how a desired outcome can be reached.
As we’ve already learned in a previous article, humans learn by adapting their behavior based on previous experiences. Similarly, machines learn by adapting their behavior based on data. And for humans and machines alike, making mistakes is a crucial part of this learning. We need to understand what works and what doesn’t in order to know how to successfully perform a task.
The main goal of this learning is to detect reliable patterns and characteristics in our experiences – or in the context of machines, in the data – which consequently allow us to take the correct actions.
Here are a few examples of learning from experience:
- Before you leave the house, you notice there are rain clouds overhead – so you take an umbrella with you to prevent yourself from getting wet!
- Due to heavy traffic in the morning commute, you need to get up early to reach work on time. However, after the summer holidays start, there are far less people on the road – so you know you can stay in bed longer.
- The demand for chocolate croissants is 2.3 times higher in the morning than in the evening, except for weekends where it is 0.8 times less. Given that yesterday was a Monday and you sold 100 chocolate croissants in the evening, you know you’ll need to bake 230 croissants for your customers this morning.
- Spinach is grown in a greenhouse at around 25-27°C. On one particular patch, the usual emerald green foliage has a slightly red discoloration. This is typically related to a deficit in nutrients XYZ. Given that the red discoloration is somewhere between a mahogany and a merlot red, you know that you’ll need to add 0.5ml of fertilizer ABC.
Given enough time, most of these relationship patterns can be observed and discovered by humans. But what if you need to consider 20 different pieces of information to decide what to do? And what if it’s actually 1,000 pieces of information?
The sheer number of data points, the complexity of the problem, and the subtlety of differences in patterns make this task very difficult for humans – but, most of the time, it is very easy for computers to work it out. Even better, by simulating the outcome of millions of different scenarios, a machine can quickly assess what does and doesn’t work before choosing the best strategy to reach its goal.
But how does machine learning actually work?
The main goal of the machine learning process is to establish a model that describes our data accurately, which then allows us to make predictions about the future based on genuine insights.
For example, take the weather model meteorologists use to predict tomorrow’s temperature, humidity or probability of precipitation. For data the model takes the weather events from the past and combines them in such a way that accurate weather predictions for the future are possible.
Alternatively, consider a face detection model that learns how to combine multiple pixels in an image to detect the location, shape and form of a human face. Or a navigation model for a self-driving car that learns how to safely navigate the road from a multitude of environmental sensors.
These are all models that try to describe a particular task: how the weather evolves over time, what the human face looks like, and how to drive on the road from the perspective of a car. And all of these models were trained with the help of specific datasets. By analyzing the information patterns in the data, a machine ‘learned’ the optimal interpretation of that data to predict a desired outcome. In other words, the machine learned a model of how to work with the data.
So, how does it actually work? Well, first we need some data and a goal. For example, let’s say we have thousands of photos of people together with their date of birth, and our goal is to predict the age of a person in a given photo. Once this is clear, we can choose an appropriate model, train it on the data at hand and we’re good to go.
In future articles we will discover the various different models and examine situations where they might be useful. For now, we’ll look at two approaches towards training a model: the iterative (or step-by-step) approach, and the all-at-once (or brute force) approach.
The iterative training approach
In an iterative training approach, the AI model learns through trial and error in order to eventually perform a task successfully.

The first time we feed data into our model, the prediction will be unreliable. The model can use the data to train itself, but it will make many mistakes because it has never seen this type of data before – the model doesn’t know what is helpful and what is not. In other words, the model’s internal parameters (the ‘lever’, ‘cogs’ and ‘pulleys’ inside the machine) are set more or less randomly. Nonetheless, we ask the model to make predictions and measure its performance.
For example, if we ask it to predict the age of a person in a photo, the model might be 40 years off with its predictions. This is not a good performance, but knowing how bad it is will allow us to switch, turn and move some internal model parameters so as to hopefully improve the model’s performance. If it improves, then we should continue in the same direction. If it gets worse, we should reverse our steps and try something different. That is how an iterative model trains.
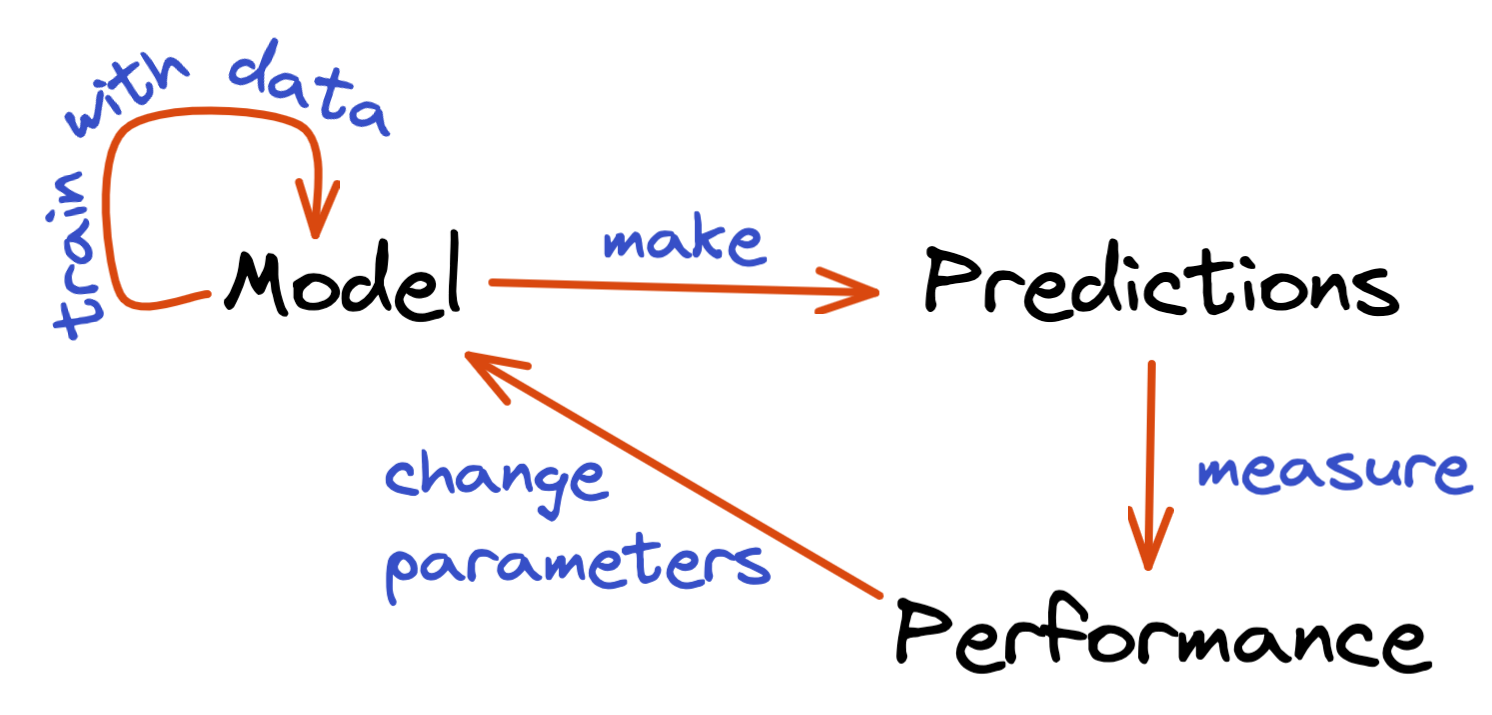
It is through this loop – changing the model parameters, training the model to make new predictions, measuring the current performance and changing the model parameters some more – that the model ‘learns’ the right internal parameters.
In this context, the learning happens when the tunable model parameters are adapted to fit the observed data. In short, the model learns from the data. Then once the model with all of its parameters has been trained and optimized, it can be used to predict the outcome of newly observed data.
It is important to note that this process might not work, or only work very, very slowly, if the framework of model optimization is not set up in an optimal way. This is where human expertise and knowledge comes into play. Knowing a bit about the data and the model at hand, we can help the AI to change the model parameters in a reasonable way and approach the optimal solution at a good pace.
The all-at-once training approach
In an all-at-once training approach, the AI learns the best model parameters by exploring many different parameter constellations at once. Whereas in the iterative approach the model ‘learns from its mistake’, this is not the case with the all-at-once approach. Instead, the AI simply tries out multiple versions of the model, all with different parameters, and sees what works best.
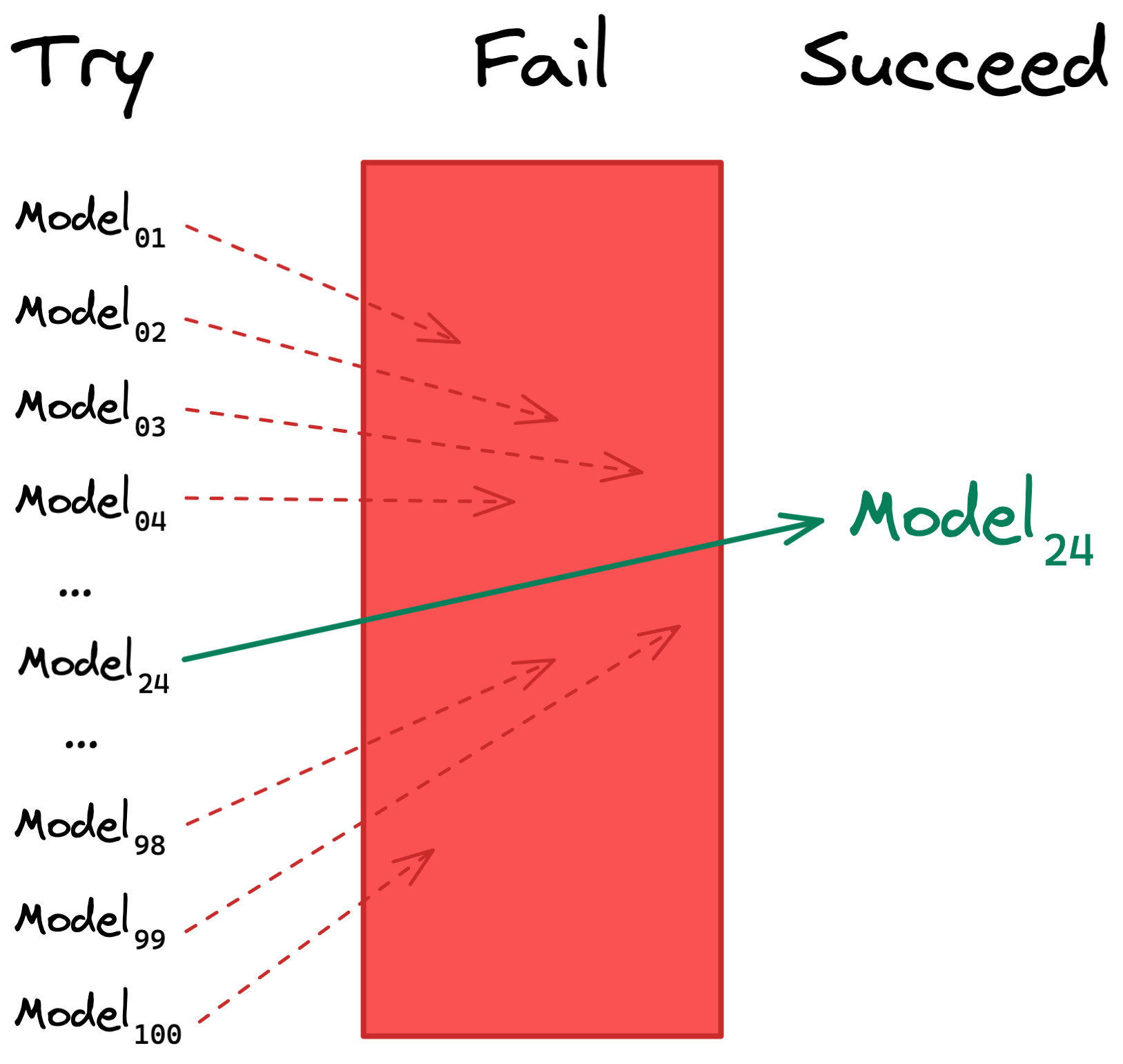
The trick with this kind of learning approach is to keep the number of models you want to try out down to a reasonably low number, because some models have a mind-boggling amount of possible parameter combinations. Once more, this is where human expertise comes into the loop: we can help guide this model exploration by restricting the potential model parameters to something that makes sense and can be explored in a reasonable timeframe.
When can we use machine learning?
Machine learning is ideal for training on large amounts of data. And using machine learning definitely beats manual coding if there are a lot of small details that need to be taken into account for the final decision.
However, machine learning (or AI for that matter) is not always the answer to all of our data problems. Sometimes ‘standard’ rule-based programming (e.g. if a customer is in front of a sliding door and the sliding door is closed, then open the sliding door) is better and more robust than using an AI model. But if the problem at hand is very complex and traditional approaches do not yield good results, then machine learning could certainly be applied.
Alternatively, if the model needs to be deployed in a dynamically changing environment, an AI model can be tasked to adapt itself to the new environment should something change. In other words, the model can quickly adapt to new data and changing patterns.
Will this process always work?
Ideally, yes – the process should usually yield positive results. But the reality is always more complicated.
The approach described above should lead to the most optimal model, given the particular input data and constraints of the model parameters that the AI is allowed to explore. However, depending on the quality and content of the input data2, and the inherent restrictions of the model, the predictions can be more or less useful.
For example, a very simple model with just a few parameters might be good to predict your height at age 20, but will not be capable of driving an automated car in a snow blizzard. For this we need a complex model with billions of different parameters, capable of accurately modeling the complex reality on the road.
However, the more complex the model and the property we want to learn, the more data is needed – just having a five-minute video recording of a car driving in the parking lot will not be enough to train a fully autonomous all-terrain vehicle.
And even if we have the right model and the right amount of data, the predictions might still be useless in the real world if the data is not representative of the problem you are trying to solve. For example, if you want to have a face detection algorithm capable of unlocking a phone, then you need data representing the full spectrum of people who might use such a phone: i.e. all combinations of gender, age, ethnicity, culture, handicap, fashion, and so on.
If some populations are under-represented, then your algorithm will fail in detecting their faces, and as a consequence will discriminate against them. However, this isn’t because the model wasn’t trained sufficiently, but because the data didn’t provide this pattern. This is a potential issue that the human in the machine learning loop should recognise and thus seek to address.
If you would like to know more about this, then you might be interested in our article AI and Ethics.
Human versus machine - should we automate everything?
Human versus machine isn’t necessarily the endgame; while machine learning is largely an automated process, it still needs human guidance. We cannot just throw our data into a machine learning algorithm and hope for the best.
Instead, a big part of the success of the machine learning process comes down to making a series of informed and smart decisions. These start with deciding what parts of the data to use, how to best combine different parts of the data, which algorithms to combine, what parameter combinations to allow, and how these algorithms should optimize their internal parameters.
As with many new technologies, the ultimate goal of machine learning is to free humans from tedious and dangerous tasks through automation, and to help us discover and innovate by providing a non-human perspective on our challenges.
-
According to Wikipedia, ‘learning’ is the process of acquiring new understanding, knowledge, behaviors, skills, values, attitudes, and preferences. ↩
-
Keep in mind that an AI model can only learn what’s in the data. For example, if the only information you have about a patient is their hair color and last name, you won’t be able to train a model to predict the patient’s gender or height; this information is simply not in your dataset. ↩