We now know that artificial intelligence (AI) exists all around us, but it’s still difficult to grasp how this technology actually works. Where can we “see” it in action? And how can we identify which systems use AI technologies and which ones don’t?
We’ve learned to accept that advanced AI systems can perform tasks like detecting spam in our inbox, or recognizing our face when we unlock our phones. But for most of us, how AI actually manages to do these things remains a mystery.
Even if we understand that AI needs data to “learn” from, who is the “teacher” in this scenario? Where does the data come from? Who does the teaching and the grading? Underneath the smart exterior, is AI just a lot of highly sophisticated code written by clever programmers, or has it somehow been brought to life and become capable of learning on its own?
In this article we’ll explore these questions and more. We will slowly pull back the curtain to reveal what AI technologies are made of and how they learn from data. Our intention is to blow away some of the myths surrounding AI by showing some of its inner workings. There is no magic or hocus pocus at work here – only processes which can be understood with a little investigation.
By the end of this article you will be able to see that this technology is exciting without being scary, and that its fundamental building blocks are not difficult to understand. The aura of mystery surrounding AI is because we struggle to comprehend its ability to quickly absorb vast quantities of data and observe patterns in it – and not because there is some sort of ghost in the machine.
How AI can predict your weight.
When AI performs one of its “wonders”, it’s not doing anything too much different from what a human would do in the same situation. Let’s begin by considering a very basic example.
Let’s say we want to establish a “humanity dataset”.1 For this we might record things like age, height, weight, hair color, etc. And in tabular form that data might look something like this:
| Id | Age (years) | Height (cm) | Weight (kg) | Hair color | Sporty | Sex |
|---|---|---|---|---|---|---|
| 1 | 16 | 174.3 | 58.6 | Brown | Yes | Female |
| 2 | 25 | 166 | 64.3 | Blond | No | Male |
| 3 | 2 | 88.8 | 11.9 | Black | No | Female |
| 4 | 61 | 175.8 | 72 | White | Yes | Male |
| 5 | … | … | … | … | … | … |
Now, let’s say we would like to create an AI system that is capable of predicting the weight of a person, based on their personal features. For example, let’s consider children from ages two to eight years old.
Feature
In the context of AI, we call a single measurable characteristics of an observed phenomenon a feature.2
For example, a feature of a person could be their hair color, age, height, etc. In a tabular dataset, these kinds of features are stored in columns, as shown in the table above. Since these features can vary from one observation (here individual people) to the next, they are often referred to as variables.
We know from our own lived experience that toddlers don’t weigh very much, but as they grow into older children, they become taller and heavier. We can check whether our intuition is correct by plotting the weight and height like so:
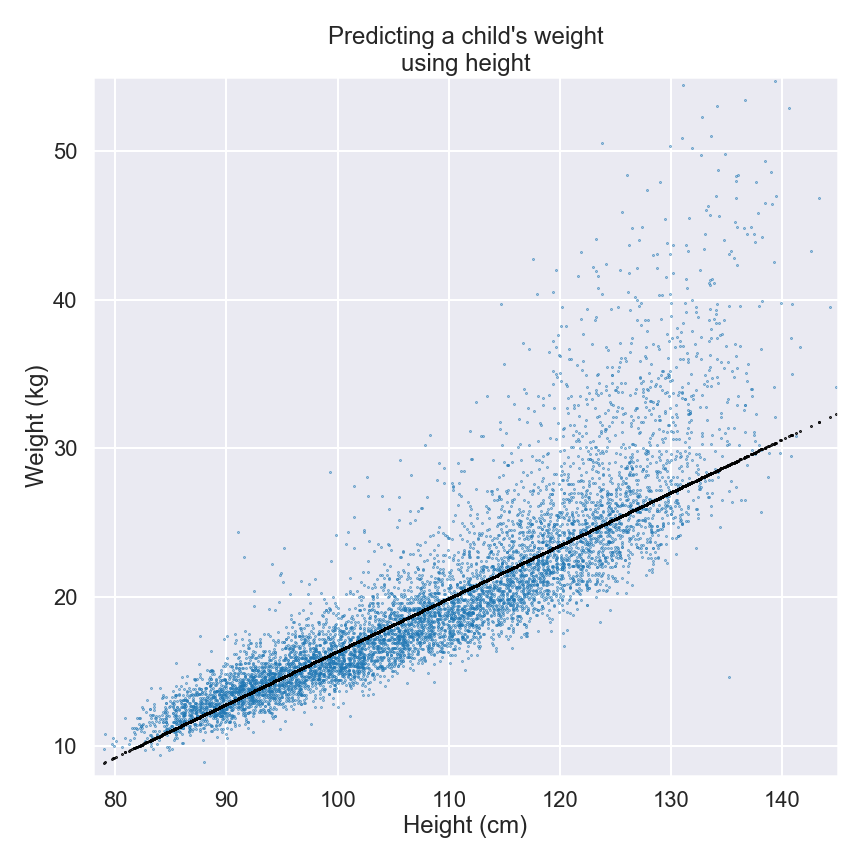
Each blue dot represents an individual child, with the height of the child on the horizontal x-axis and the weight on the vertical y-axis. Looking at the plot, it’s easy to see a relationship between height and weight: as the children get taller, they also get heavier. There is a clear pattern that confirms our initial intuition.
Now that we’ve confirmed this relationship between height and weight, can we create a model that explains how they are related? In other words, if we know the height of a child, can we produce a reasonable estimate of their weight?
Model
In the world of AI (and mathematics in general), a model is used to describe the relationship between several variables or features. Typically we try to describe one feature (the output) in terms of some of the others (the inputs).
For example, the radius, the area, and the circumference are all observable features of a circle. A model of the relationship between the radius r and the circumference C would be given by the equation C=2πr, that is to say for any circle the circumference is 2π (about 6.3) times as long as the radius.
Let’s return to the plot for a moment and look at the black line indicating the overall trend. What does this line represent? Can it help us estimate the weight of a child if we already know its height?
The black dots that form the line represent the height and weight of average children. The average 80cm child weighs around 9.5kg, rising to 27kg by the time the child has grown to 130cm. We can also calculate that the average child gains about 0.35kg for every additional centimeter in height.
The black line gives us just the kind of model we’re looking for. We start with 9.5kg at 80cm and for every extra centimeter in height we add 0.35kg. This model isn’t perfect, because we can see lots of blue dots above and below the line, but it is certainly better than a random guess and it provides us with a reasonable estimation of weight.
The key piece of information that allows the model to work is the 0.35 kg/cm ratio that tells us how much weight we need to add for each extra centimeter in height. When we talk about models in AI, a number like this is known as a parameter. And when we build a model, we can adjust our parameters as we see fit. Choosing parameters and setting them so that the model is useful is obviously very important.
Parameter
In an AI model, a parameter is a model-specific numerical value that, unlike the value of features, is constant and independent from the observations we make. Different circles have different radii and circumference. However, the number we multiply the radius by, that is 2π, is the same for all circles. When an AI model is “learning from data”, it is trying to find suitable values for its parameters. Parameters may for example give a weighting to a specific feature, or they may capture a threshold above which the overall behaviour changes, e.g. the age of puberty.
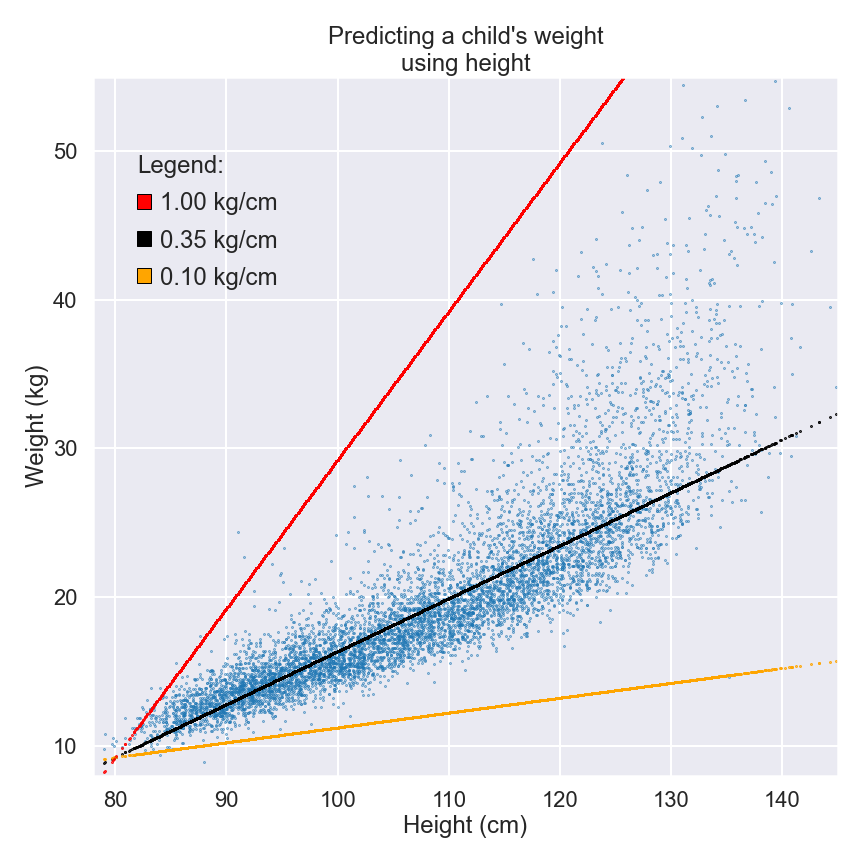
For example, lowering our parameter to 0.1kg/cm produces the orange line in the plot above. We can clearly see that this new line underestimates the vast majority of weights by quite a big margin. According to this parameter, the average 130cm child would weigh only 14.5kg.
At the other extreme, the red line shows what happens when we adjust the parameter to 1.0kg/cm. This estimates that the average 130cm child would weigh 59.5kg, which we know is way over the average for a child of that height. Neither of these adjusted parameters provides as good a model as the original 0.35kg/cm scale represented on the black line.
So, how did we arrive at our parameter of 0.35kg/cm? We did it by analyzing the data and working out the weight of an average child at a given height. This is a really important point, so let’s repeat it for emphasis: we used the data to find the parameter for our model.
Without data, we couldn’t have built the 0.35kg/cm model and would’ve had to rely on guessing instead. But by analyzing the data, we “learned” that a good parameter for height in our selected age group is 0.35. In other words, the model learned from the data.
You will encounter many, many statements like this in discussions about AI. The key thing to remember is that analyzing data gives us the ability to identify suitable parameters for our models.
More Data, More Insights
Now let’s add some other features and see what happens to our model. Perhaps we can make it more effective by capturing extra data to build up a more detailed and effective pattern?
As an example, let’s see what happens when we try to estimate weight by using gender as well as height.
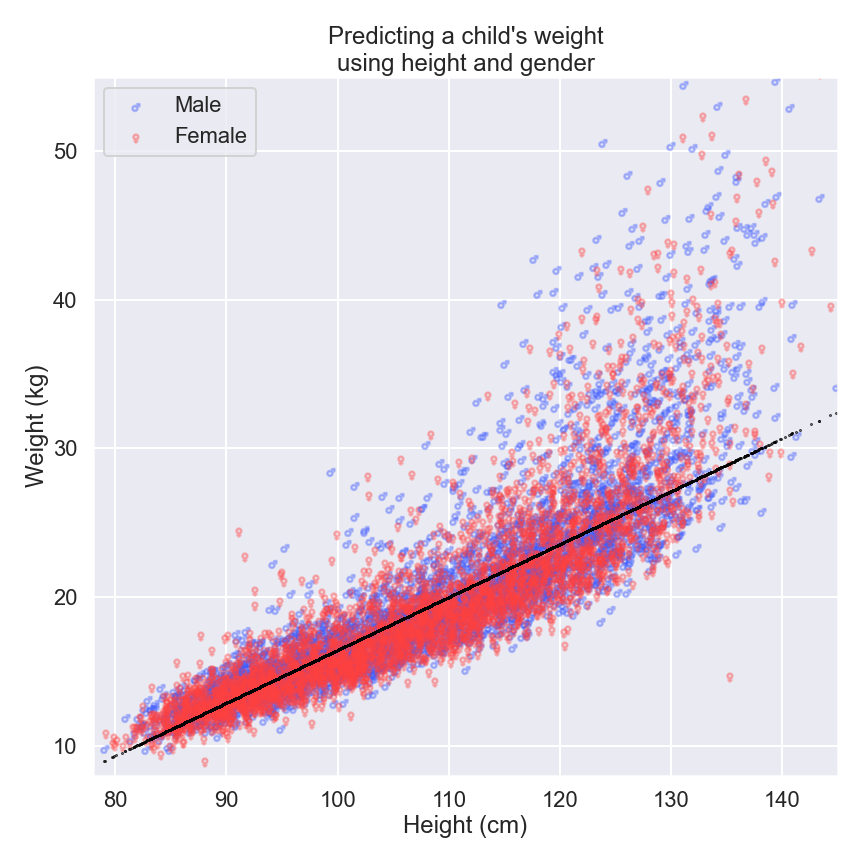
This time our model has two parameters: we keep the parameter for height (0.35), but add a second parameter for gender (-0.18). This means that we need to add 0.35kg for every extra centimeter in height, but we then need to subtract 0.18kg if we are estimating for a girl instead of a boy.
Let’s pause for a moment to think about what this really means for the model.
If a girl is only 0.5cm taller than a boy – a difference so small that we’d struggle to see it with the naked eye if we stood them back-to-back – our model would predict the same weight for both. What exactly has happened here? Well, the model has “learned” from our “humanity dataset” that gender isn’t really useful for predicting weight in our selected age group. How cool is that?
Our initial dataset was restricted to children up to the age of eight, but what happens when we look at older individuals?
Again, we know a couple of things from experience. Firstly, we know that we eventually stop growing when we reach adulthood. Secondly, we can continue to gain or lose weight throughout the various stages of our lives.
If we consider this much fuller set of data, we soon realize that predictions based on our previous model aren’t much use as our subjects get older. In the next figure, we can see that as a person gets taller, the spectrum of potential weights becomes much broader.
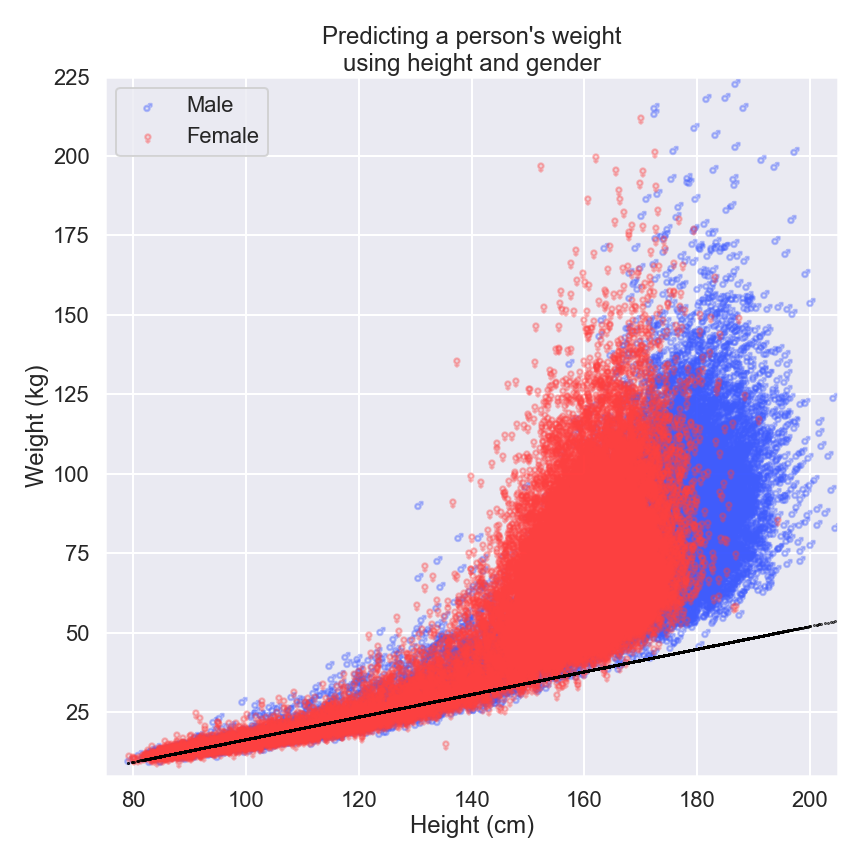
Health and lifestyle can give us weight measurements that are seemingly unpredictable. Our features for height and gender are no longer sufficient for predicting weight in adults, and our idea that every additional centimeter in height produces the same change in weight isn’t much use either.
To build more intricate and complex models – like the one represented on the red line in the graph below – we need to find ways of introducing more and more features into our models. But as models become more complex, the amount of data they require to learn from and the number of parameters they intend to estimate increases massively.
Fortunately, computers can juggle hundreds of parameters at once without any problems.
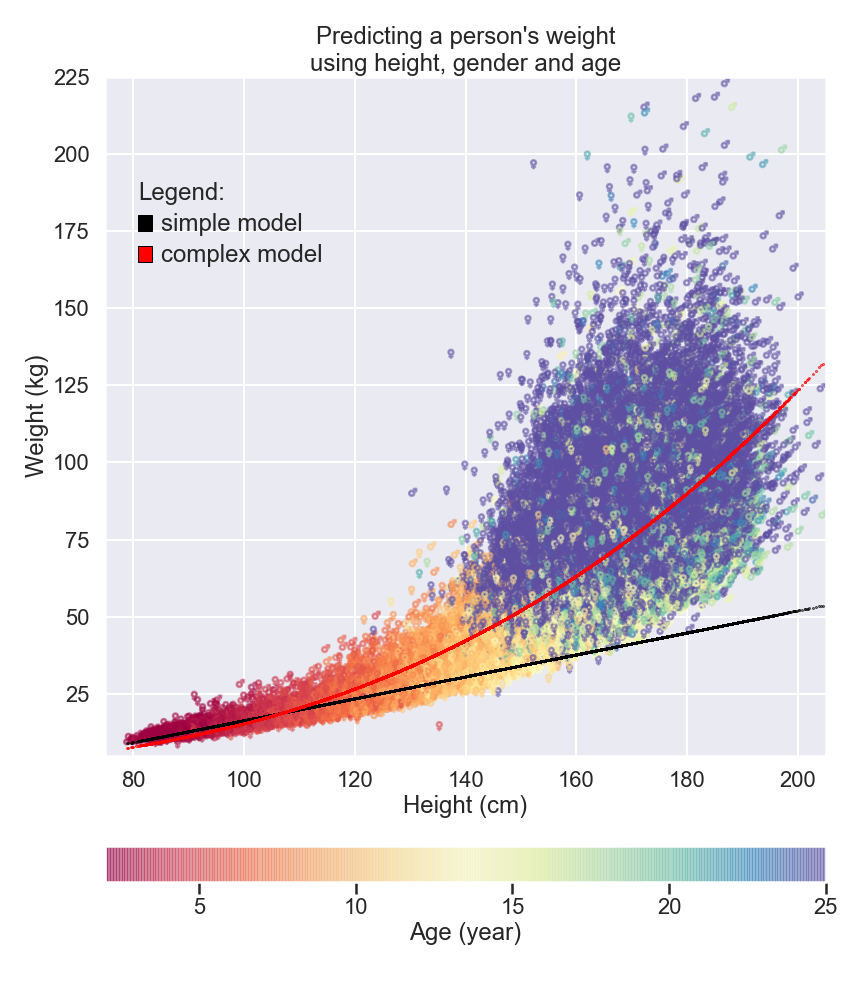
Tell the AI More – and Get Better Models
This is what is so fascinating about AI systems: if they are given enough data, and if that data covers enough different cases of “humanity”, an AI system can discover many/numerous relevant patterns and derive parameters from them. By continuing to add features, a more nuanced pattern of human nature can be covered.
Eventually, with enough features, we get to the point where we can predict the weight of nearly any person with a high degree of confidence: “A person of this height, this gender, this age, with these many children, this household pet, living in this location, with this educational background, marital status, and genetic predispositions… weighs approximately 78.3kg.”
All we’re still trying to do is predict the weight of a person, as we did in the very first figure in this article. Now, however, we have much more detail in our dataset and are looking for more than just a handful of parameters.
If a dedicated data scientist tried to build our first model with just one feature by manually inputting the heights of 10,000 children into a pocket calculator, it would take roughly three hours. Suffice to say we wouldn’t recommend trying this at home!
An AI system can look at numerous human features at the same time, quickly identify relative patterns and information, and then use them to create the parameters required to perform our desired task – predicting a person's weight, for example.
Looking at data and developing parameters has been done by mathematicians, statisticians and scientists since the 1800s. But manually finding the most effective parameters for all of the features in this dataset would be very difficult, and covering all underlying causes of human body weight would be practically impossible. AI systems are in a much better position to do this because they can analyze huge amounts of data in a very short time.
Newly-developed approaches are giving AI systems even more flexibility and ability to find the optimal combination of parameters for any given task. They do this by trying out different parameter combinations, checking how well they perform, and then adapting them accordingly. This process is repeated until the predictions being made are sufficiently accurate.
Note: an AI system capable of looking at this data to predict a person’s weight could just as easily use it to learn how to predict age or height. All the AI system needs is the dataset, the features it’s allowed to look at, and the target. Then once the parameters are found and the model is trained (which might take quite some time), it can be used to instantly predict the age or height of any new individual.
The implications of learning from data.
The ability to “learn from data” also comes with its limitations. An AI system can only predict the weight of a person with accuracy if there are comparable people in the dataset from which it learned.
If an AI system were to look at a dataset of the current Swiss population, it would be able to do a good job of predicting the weight of an average Swiss person. However, it would likely struggle to make an accurate prediction in rare cases where someone is either extremely light, or extremely heavy.
If an AI system has never seen a person weighing 300kg (meaning that such a person wasn’t included in the dataset), then it wouldn’t be able to accurately predict their weight. And how precise do you think our model would predict the weight of somebody like Robert Wadlow,3 who at 272cm was the tallest man who has ever lived? For example, our particular AI system has the problem that it will blindly multiply Wadlow’s unusual height with the parameter learned from the height of an average person.
In other words, an AI system can learn incredibly complex information patterns from any dataset, but it can't predict anything beyond what it was initially trained on. This is because it is limited by the features provided in the data, not its ability to analyze it.
The difference between AI and smart applications
AI is the emerging technology. It’s exciting, full of possibilities, and gets a lot of coverage in the media. The hype around AI means businesses and marketing companies try to advertise products and services as “smart”, or possessing some sort of AI technology wherever they can. However, lots of programs and gadgets that do “smart” things don’t use AI at all.
Now that we understand a bit more about what AI systems actually do, we can identify other such systems and distinguish them from sophisticated computer programs that appear to be AI, but actually aren’t.
Let’s summarize the key characteristics of AI as briefly as we can:
- It has the ability to analyze huge amounts of data.
- It automatically finds hidden information patterns in that data.
- It uses these patterns to choose model parameters that will perform our task most effectively.
Depending on the model, your “smart” watch might not be as smart as you think. Showing your heartbeat and counting the number of steps you take each day doesn’t require any AI system; collecting this kind of data can be done with well-placed sensors.
If a device is simply reporting numbers without analyzing them, it doesn’t need AI. Even when your device decides that it’s time to tell you to get up and move more, it can simply use the sensors to measure how long you have been inactive for and send you an alert after 30 minutes, for example.
However, if your watch is actually analyzing your activity patterns and using them to work out the optimal time to motivate you, or if it’s analyzing your heartbeat and identifying irregular or abnormal heart rhythms, then an AI system is being used.
To perform these actions, your device has to analyze your data, detect patterns that are unique to you, and derive parameters in much the same way as our AI system did for predicting a person’s weight.
Summary
In this article we have taken a peek behind the AI curtain and explored the ways in which AI is able to “work its magic”. But, as we have seen, there really isn’t any magic at all – only datasets and the ability of AI systems to analyze them, find patterns, and choose parameters to perform tasks effectively.
In the next article we will explore how AI is able to read, observe and make decisions.
-
This example is based on the dataset from the National Health and Nutrition Examination Survey and covers 60,000 people. ↩
-
This definition for features is based on the famous book “Pattern recognition and machine learning” by Christopher Bishop. ↩
-
For more about Robert Wadlow, the tallest person in recorded history, check out this Wikipedia article. ↩