Nous savons tous que l’intelligence artificielle (IA) est présente partout dans notre environnement, mais il n’est pas toujours évident de comprendre le fonctionnement de cette technologie. Comment la « voir » en action ? Et comment reconnaître si un système utilise de l’IA ou non ?
Nous commençons tout juste à comprendre et accepter que des systèmes d’IA avancés puissent effectuer des tâches telles que détecter des spams dans notre boîte de réception ou encore reconnaître notre visage afin de déverrouiller notre téléphone. Mais la façon dont l’IA fonctionne reste encore un mystère pour la majorité d’entre nous.
Même si l’on comprend que l’IA a besoin de données pour « apprendre », qui est responsable de son « enseignement » ? D’où viennent les données ? Qui enseigne ? Qui corrige ? L’IA n’est-elle au fond qu’une suite de lignes de codes élaborée par d’intelligents programmeurs, ou est-elle désormais plus indépendante et capable d’apprendre par elle-même ?
Nous tenterons dans cet article de répondre, entre autres, à ces questions. Nous lèverons le voile sur ce qui constitue les technologies de l’IA, et sur la façon dont elles se développent à partir de données. Notre but est notamment d’éviter de nourrir les fantasmes qui gravitent autour de l’IA en expliquant concrètement comment elle fonctionne, nous donnant ainsi un peu de sens critique. Ici, pas de tour de magie, mais de simples processus qui peuvent être expliqués si nous prenons un peu le temps.
Après avoir lu cet article, vous pourrez constater que cette technologie est passionnante sans être effrayante, et que les éléments fondamentaux qui la composent ne sont pas difficiles à comprendre. Il y a un mystère qui gravite autour de l’IA. Pas un mystère dans le sens où un fantôme serait caché dans une machine, bien sûr, mais plutôt un mystère causé par notre propre incompréhension de l’IA et de ses capacités à assimiler de grandes quantités de données.
Comment l’IA peut prédire votre poids
Lorsque l’IA réalise une de ses « tours de magie », c’est en fait un peu la même chose que si un humain le faisait. Prenons un exemple très simple.
Disons que nous souhaitons créer un « jeu de données sur l’humanité »1. Nous allons donc enregistrer des paramètres tels que l’âge, la taille, le poids, la couleur des cheveux, etc. Ces données peuvent ressembler à ceci sous forme de tableau :
| Identifiant | Âge (années) | Taille (cm) | Poids (kg) | Couleur des cheveux | Sportif | Sexe |
|---|---|---|---|---|---|---|
| 1 | 16 | 174.3 | 58.6 | Brun | Oui | Féminin |
| 2 | 25 | 166 | 64.3 | Blond | Non | Masculin |
| 3 | 2 | 88.8 | 11.9 | Noir | Non | Féminin |
| 4 | 61 | 175.8 | 72 | Blanc | Oui | Féminin |
| 5 | … | … | … | … | … | … |
À présent, supposons que nous voulions créer un système d’IA capable de prédire le poids d’une personne en fonction de ses caractéristiques personnelles. Prenons par exemple les enfants de 2 à 8 ans.
Caractéristique
Dans le contexte de l’IA, une caractéristique correspond à une propriété ou charactéristique mesurable d’un individu ou d’un phénomène observé.2
Par exemple, une caractéristique d’une personne peut être sa couleur de cheveux, son âge, sa taille, etc. Lorsque l’on représente nos données par le biais d’un tableau, les caractéristiques sont donc les valeurs inscrites dans les colonnes, tout comme on peut le constater pour notre exemple ci-dessus.
Grâce à notre expérience personnelle, nous savons à peu près tous que les tout-petits ne pèsent pas bien lourd, mais qu’en vieillissant, généralement, ils grandissent et prennent du poids. Vérifions si cette intuition est correcte en traçant le poids et la taille comme ceci :
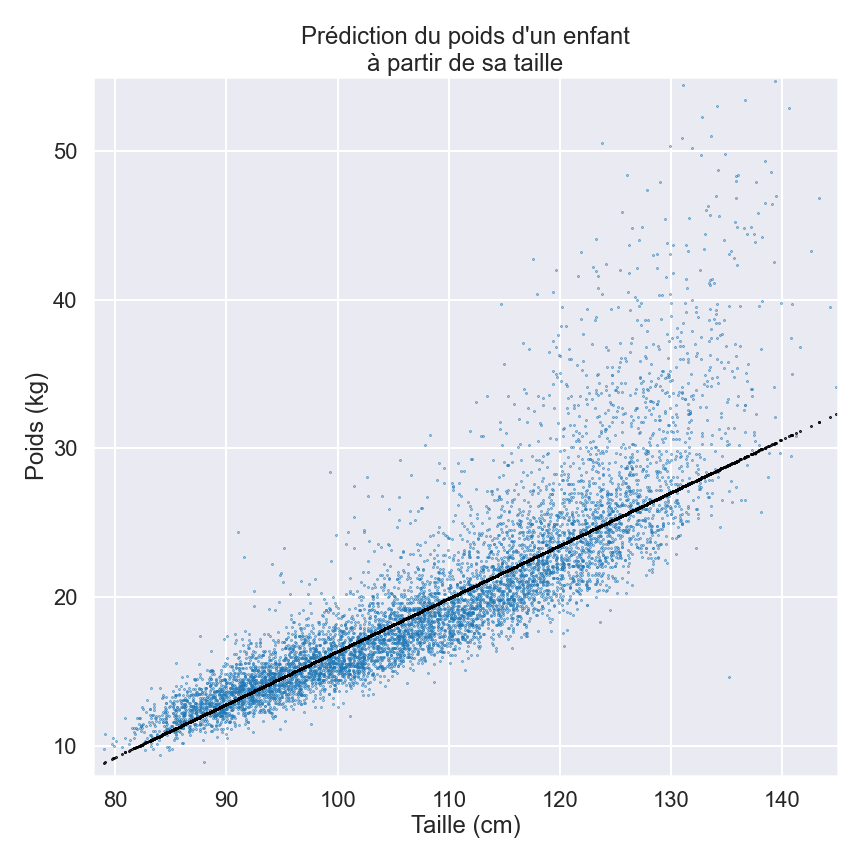
Chaque point bleu représente un enfant. La taille de chaque enfant se trouve sur l’axe des abscisses (l’axe horizontal), et son poids sur celui des ordonnées (l’axe vertical). En regardant le graphique, on voit assez facilement le lien entre la taille et le poids. Nous constatons en effet que plus les enfants grandissent, plus leur poids augmente. Notre première intuition est donc confirmée par un schéma clair.
Maintenant que nous avons constaté un lien entre la taille et le poids, pourrions-nous imaginer créer un modèle qui expliquerait ce lien ? En d’autres termes, si nous connaissons la taille d’un enfant, pourrions-nous estimer son poids ?
Modèle
Un modèle, au sens de l’IA ou plus généralement des statistiques, est un terme utilisé pour décrire une relation entre une ou plusieurs variables. Cette relation s’exprime grâce à l’utilisation de constantes (les paramètres) et de variables (les caractéristiques). Au sens mathématique, on peut aussi le voir comme une fonction.
Par exemple, le rayon, l’aire et la circonférence sont tous les trois des caractéristiques observables d’un cercle. Un modèle qui relierait le rayon r et la circonférence C pourrait être résumé grâce à l’équation C = 2πr, c’est à dire que pour tout cercle, sa circonférence correspond à 2π (environ 6.3) fois son rayon.
Revenons un moment au graphique et observons la ligne noire indiquant la tendance générale. Que représente cette ligne, et peut-elle nous aider à estimer le poids d’un enfant si nous connaissons déjà sa taille ?
Les points noirs formant cette ligne représentent la taille et le poids d’enfants dans la moyenne. Le poids moyen d’un enfant mesurant 80 cm est d’environ 9,5 kg. Il passe à 27 kg au moment où l’enfant atteint 130 cm. Nous pouvons aussi calculer qu’un enfant moyen prend environ 0,35 kg pour chaque centimètre de croissance.
La ligne noire nous donne en fait exactement le modèle que nous cherchions ! On commencerait donc avec un poids de 9,5 kg pour une taille de 80 cm puis on prendrait 0,35 kg à chaque fois que l’on grandit d’un centimètre. Ce modèle n’est pas parfait parce que nous pouvons voir beaucoup de points bleus au-dessus et en-dessous de la ligne, mais il est certainement plus fiable qu’une estimation complètement au hasard et nous donne déjà une estimation raisonnable du poids.
L’information clé qui permet au modèle de fonctionner est ce rapport de 0,35 kg/cm qui nous indique combien de kg nous devons ajouter pour chaque “cm” supplémentaire. Lorsqu’on parle de modèles d’IA, un nombre comme celui-là s’appelle un paramètre. Et ces paramètres sont des parties ajustables du modèle, qui évoluent au fur et à mesure que le modèle se construit. Le choix de ces paramètres et leurs réglages sont fondamentaux si nous voulons que le modèle soit utile.
Paramètre
Les paramètres sont des valeurs numériques qui caractérisent les modèles d’IA. A l’inverse des caractéristiques, ces valeurs sont constantes et ne changent pas en fonction de nos observations. En reprenant l’exemple du cercle, les cerles ont des rayons et circonférences différents. En revanche, le nombre avec lequel nous multiplions le rayon pour obtenir la circonférence (2π) reste le même quelque soit le cercle. Lorsqu’un modèle d’IA apprend à travers les données, il tente de trouver les meilleurs valeurs pour ses paramètres. Suivant leurs valeurs, on peut en déduire si telle ou telle caractéristique, au sein du modèle, a plus ou moins d’importance, ou si il existe un certain seul au dessus duquel la caractéristique implique des changements forts (par exemple, l’âge de la puberté).
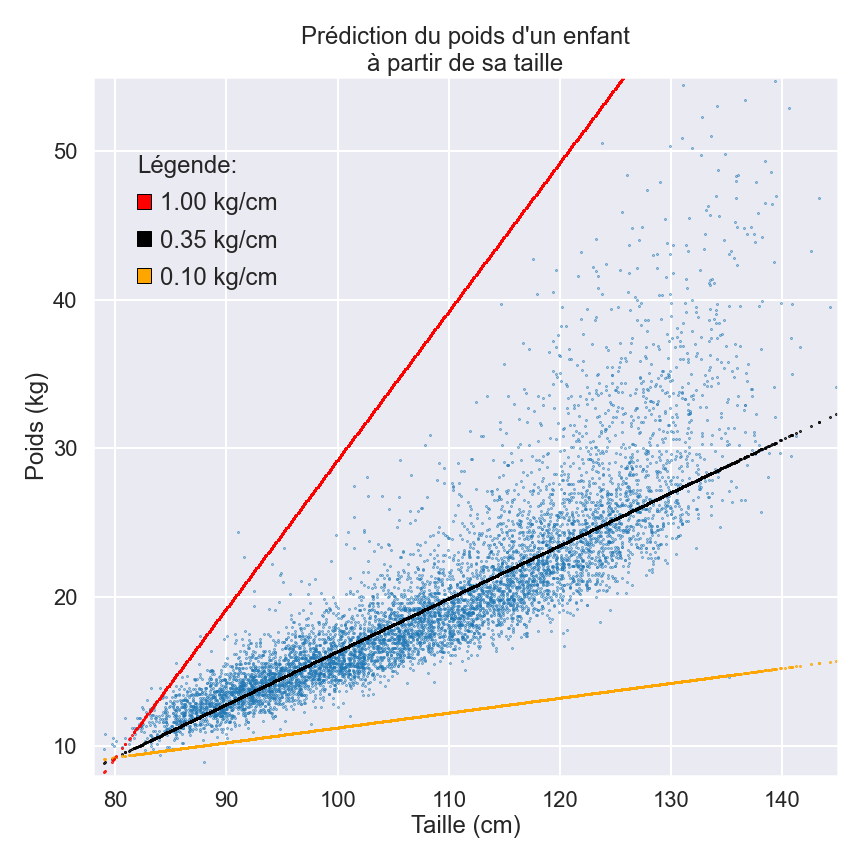
Par exemple, si l’on baissait notre paramètre à 0,1 kg/cm, on se retrouverait avec la ligne orange qui apparaît dans le graphique ci-dessus. Nous pouvons clairement voir que cette nouvelle ligne sous-estime la grande majorité des poids par un écart assez important. Selon ce paramètre de 0,1 kg/cm, un enfant moyen mesurant 130 cm ne devrait peser que 14,5 kg.
À l’inverse, la ligne rouge indique ce qui se passe si l’on modifie le paramètre à 1 kg/cm. Avec ce nouveau paramètre, un enfant moyen mesurant 130 cm devrait peser 59,5 kg, ce qui, nous le savons, est bien supérieur à la moyenne pour un enfant de cette taille. Aucun de ces paramètres ne fournit un modèle aussi juste que celui que nous avons vu en premier (de 0,35 kg/cm) représenté par la ligne noire.
Mais, comment en sommes-nous arrivés à ce paramètre de 0,35 kg/cm au juste ? Tout simplement en analysant scrupuleusement les données à disposition et en calculant le poids d’un enfant moyen à une taille donnée. C’est un point très important à ne pas oublier : nous avons utilisé les données à disposition pour trouver le paramètre qui régit notre modèle.
Sans les données, nous n’aurions pas pu construire le modèle de 0,35 kg/cm et nous aurions dû nous contenter de simples suppositions sans fondements. Mais, en analysant les données, nous avons pu “apprendre” que 0,35 était un bon paramètre dans le groupe d’âge sélectionné. En d’autres termes, le modèle a appris au travers des données.
Vous tomberez certainement sur beaucoup de formulations similaires à celle-ci si vous consultez ou participez à des discussions autour de l’IA. L’essentiel à retenir est qu’en analysant les données, nous pouvons identifier des paramètres adaptés à nos modèles.
Davantage de données, davantage d’informations
Et si l’on ajoutait maintenant de nouvelles caractéristiques dans nos données ? Observons ce qui ce passerait pour notre modèle. Nous pouvons en effet espérer le rendre plus pertinent si l’on ajoute des données supplémentaires - cela permettrait sûrement de trouver des informations et tendances plus précises encore.
Par exemple, que se passe-t-il si nous essayons d’évaluer le poids en ajoutant au critère de la taille celui du sexe ?
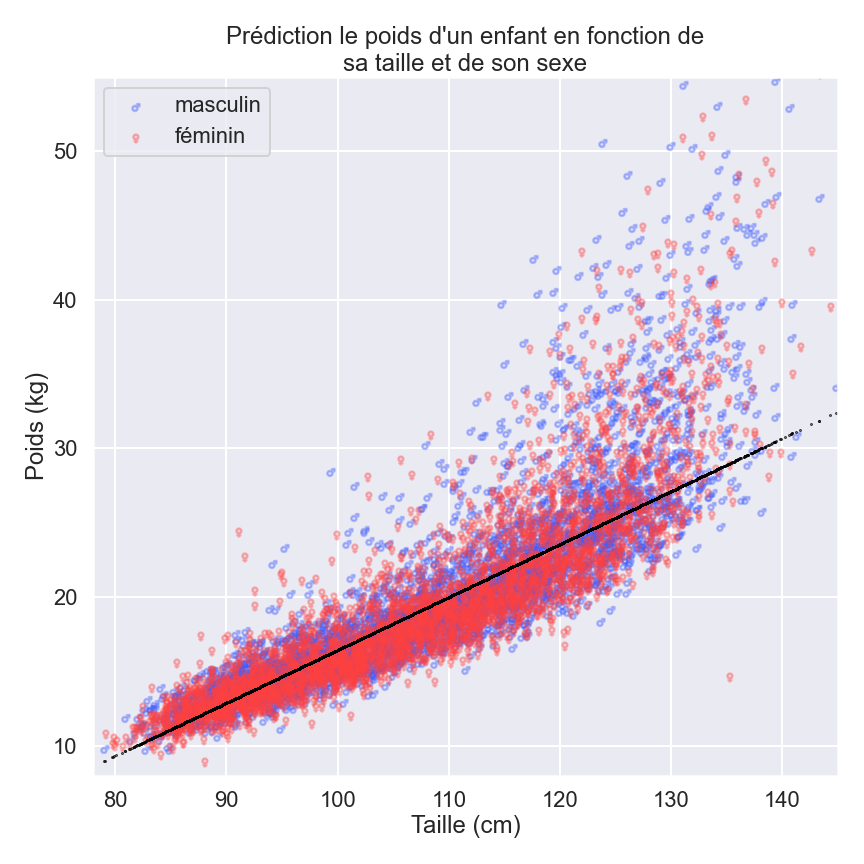
Notre modèle comporterait donc cette fois deux paramètres. Nous conservons le paramètre pour la taille (0,35) mais nous ajoutons un deuxième paramètre pour le sexe (-0,18). Cela signifie que nous devons ajouter 0,35 kg pour chaque “cm” supplémentaire de hauteur, mais nous devons ensuite soustraire 0,18 kg si l’estimation recherchée concerne une fille plutôt qu’un garçon.
Arrêtons-nous un instant pour comprendre ce que cela signifie vraiment pour le modèle.
Si une fille ne mesure que 0,5 cm de plus qu’un garçon, une différence si petite que nous aurions du mal à la voir à l’œil nu s’ils se tenaient dos à dos, notre modèle prédirait alors le même poids pour les deux. Que s’est-il passé exactement ? Le modèle a « appris » grâce à notre « ensemble de données sur l’humanité » que le sexe n’est pas vraiment utile pour prédire le poids dans le groupe d’âge sélectionné. C’est génial, non ?
Notre ensemble de données initial ne représente que des enfants de 8 ans et moins, mais qu’arrive-t-il à mesure que nos sujets grandissent ?
Encore une fois, notre expérience peut nous guider. Nous savons déjà qu’à l’âge adulte, nous cessons tous de grandir. Et nous savons également que notre poids, lui, continue à varier selon les différentes étapes de notre vie.
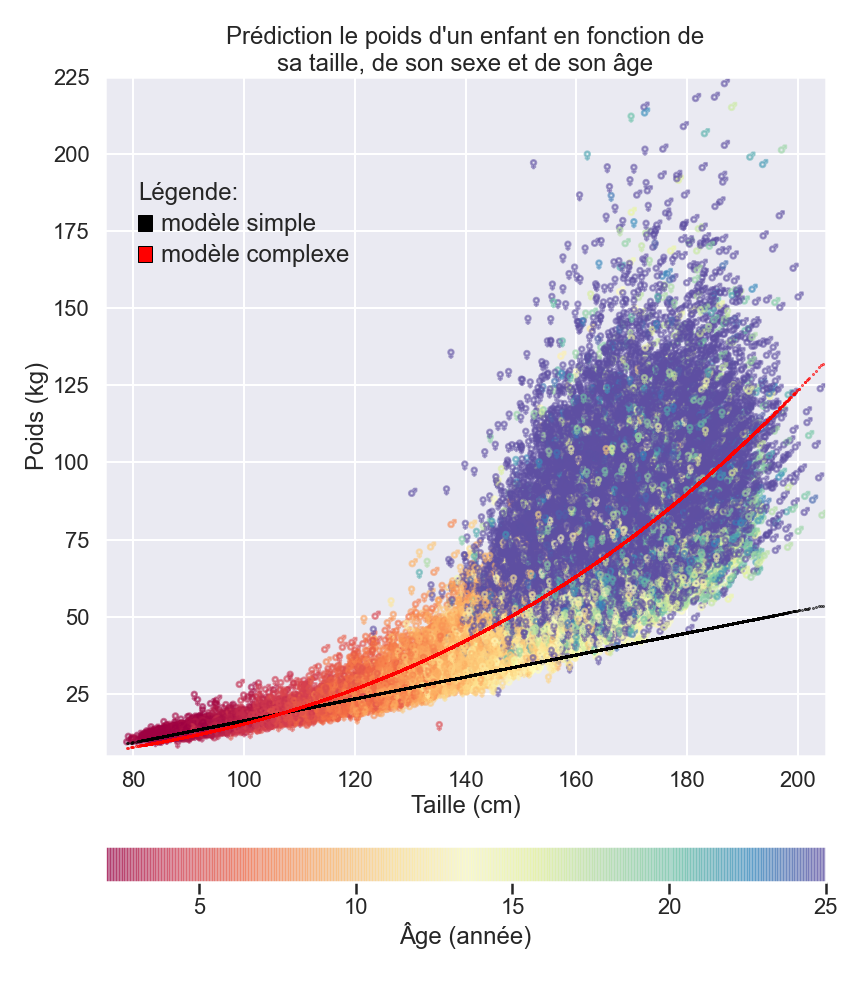
Si nous ajoutions des sujets adultes à notre ensemble de données, nous nous rendrions vite compte que les prédictions fondées sur notre modèle précédent ne seront plus très pertinentes à mesure que les sujets vieillissent. Sur le schéma suivant, nous pouvons voir qu’à mesure qu’une personne grandit, le champ des possibles de son poids devient de plus en plus grand.
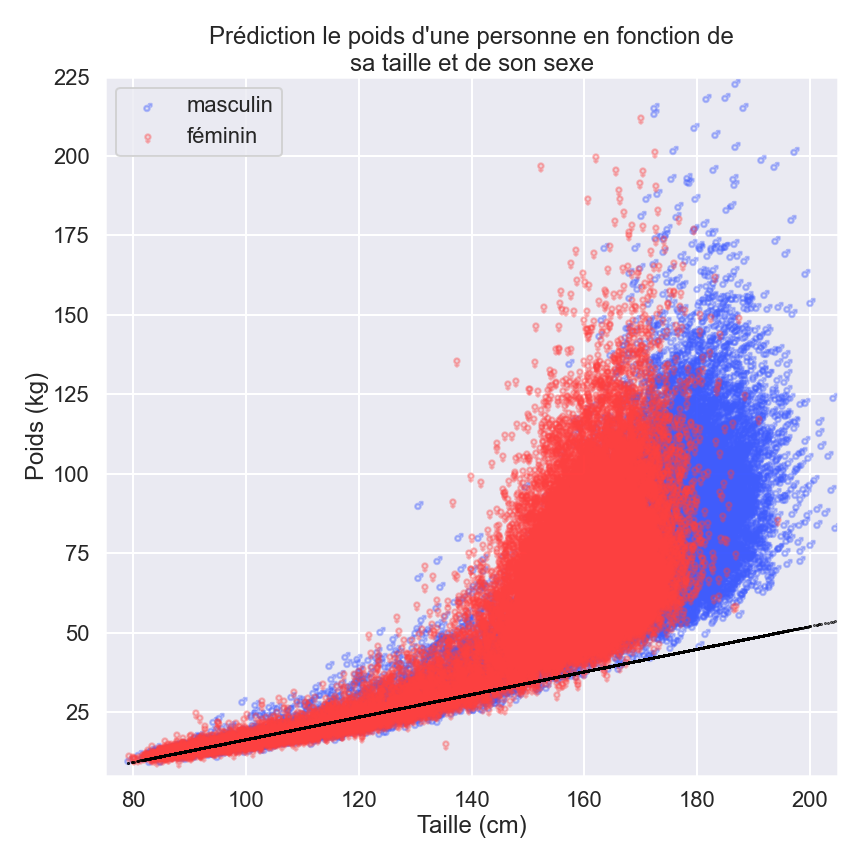
La santé et l’hygiène de vie ont un si grand impact sur le poids qu’il en devient quasiment impossible de le prédire en ne considérant que la taille et le genre d’un individu. Les informations sur la taille et le sexe d’un individu ne sont désormais plus suffisantes pour prédire son poids une fois adulte et notre hypothèse que chaque “cm” supplémentaire impliquerait à son tour une augmentation du poids n’est plus valable non plus.
Pour construire des modèles plus complets et plus complexes, comme celui représenté par la ligne rouge sur le graphique ci-dessous, nous devrions donc trouver des manières d’inclure de plus en plus d’informations pertinentes dans nos données afin de perfectionner nos modèles. Sauf qu’à mesure que les modèles se complexifient, la quantité de données nécessaire pour leur « apprentissage » ainsi que le nombre de paramètres qui les caractérisent augmentent considérablement.
Heureusement, les ordinateurs peuvent jongler avec des centaines de paramètres à la fois sans aucun problème.
Dites en plus à l’IA, et elle s’améliorera
Et c’est ce qui nous fascine tant dans les systèmes d’intelligence artificielle. Un système d’IA pourra découvrir de nombreuses tendances et déduire bon nombre de paramètres si on lui donne assez de données et si ces données sont suffisamment représentatives des humains. Plus nous ajoutons de caractéristiques dans nos données, plus les tendances identifiées par le modèle seront capables de représenter la nature humaine avec toutes ses nuances.
Sous couvert d’avoir suffisamment de caractéristiques à disposition, nous arrivons finalement à pouvoir prédire le poids de presque n’importe quelle personne de manière fiable : « Une personne de telle taille, de tel sexe, de tel âge, avec tant d’enfants, tel animal de compagnie, vivant dans tel endroit, avec telle éducation, telle situation familiale, et telles prédispositions génétiques… pèse environ 78,3 kg. »
Tout ce que nous essayons de faire depuis le début de cet article, c’est de prédire le poids d’une personne. Nous disposons maintenant de beaucoup plus de détails dans notre jeu de données, et nous pouvons donc être plus ambitieux qu’au début, lorsque nous ne cherchions que quelques paramètres.
Si un scientifique essayait de construire notre premier modèle en n’utilisant qu’une seule caractéristiques - il faudrait rentrer manuellement toutes les tailles de 10’000 enfants sur une calculette et cela lui prendrait environ 3 heures. On ne vous le conseille pas.
Un système d’IA peut observer de nombreuses caractéristiques humaines en même temps, y identifier des tendances et des signaux faibles, puis les exploiter pour définir les paramètres requis par tâche que l’on souhaite effectuer, ici par exemple évaluer le poids d’une personne.
Triturer les données et définir des paramètres sont des choses effectués par les mathématiciens, statisticiens et autres scientifiques depuis les années 1800. Sauf que trouver manuellement les paramètres les plus pertinents pour chacune des caractéristiques de notre jeu de données serait très difficile, et prendre en compte tous les tenants et aboutissants du poids d’un corps humain serait pratiquement impossible. Les systèmes d’IA, qui sont réputés pour pouvoir analyser un grand nombre de données en très peu de temps, sont donc le meilleur outil pour ce faire.
Des nouvelles approches donnent même aux systèmes d’IA encore plus de flexibilité et de moyens pour trouver par eux-mêmes la combinaison optimale de paramètres associés à une tâche donnée. Ils tentent différentes combinaisons de paramètres en calculant si, avec ces paramètres, la performance du modèle s’améliore ou empire, et s’adaptent en fonction. Ces processus se répètent jusqu’à ce que les prédictions du modèle soient suffisamment bonnes.
À noter : Un système d’IA capable d’examiner ces données pour prédire le poids d’une personne pourrait tout aussi bien les utiliser pour apprendre à prédire l’âge ou la taille. Le système d’IA n’a besoin que d’un jeu de données, de caractéristiques qu’il doit prendre en compte et un objectif à prédire. Ensuite, une fois qu’il a trouvé les paramètres et a « appris » (ce qui peut prendre un certain temps), il peut être utilisé pour prédire instantanément le poids de tout nouvel individu.
Les implications de pouvoir « apprendre » à partir de données
La capacité à « apprendre à partir de données » a des limites. Un système d’IA ne peut prédire correctement le poids d’une personne donnée seulement s’il existe déjà des individus semblables dans l’ensemble des données sur lequel il a appris.
Si un système d’IA examinait un ensemble de données de la population suisse actuelle, il serait en mesure de prédire correctement le poids moyen d’un Suisse. Cependant, il lui serait probablement difficile de le faire de façon aussi précise dans les rares cas où l’individu pèse très peu, ou est au contraire en surpoids.
Si le système n’a jamais rencontré de données concernant une personne pesant 300 kg, il ne pourra pas évaluer correctement son poids. De même, si nous voulions évaluer le poids d’une personne aux caractéristiques très inhabituelles, comme Robert Wadlow3, un américain né en 1918, qui du haut de ses 272 cm était l’homme le plus grand qui ait jamais vécu, le système d’IA ne serait pas en mesure de savoir qu’il s’agit d’un cas extrême ou inhabituel. Il prendrait donc la valeur de la taille, en ce cas présent un nombre très grand, et la multiplierait par son même paramètre, tout comme il l’a fait à chaque fois.
Les conséquences seraient probablement une surestimation du poids et donc une mauvaise prédiction. En effet, dans notre exemple, le système d’IA ne peut avoir qu’un seul paramètre pour chaque caractéristique, et il l’appliquera aveuglément et sans hésitation.
En d’autres termes, un système d’IA peut apprendre à trouver des tendances incroyablement complexes à partir de n’importe quel jeu de données, mais il ne peut rien prédire au-delà de ce sur quoi il a été initialement entraîné. Il est en effet plutôt limité par les caractéristiques à disposition que par sa capacité à les analyser.
La différence entre l’IA et des applications intelligentes “classiques”
L’IA est la technologie émergente. Elle est passionnante, pleine de possibilités, et très prisée par les médias. Le buzz médiatique autour de l’IA nous montre que les sociétés et les agences de publicité essaient de vendre des produits et services « intelligents » ou possédant une sorte d’IA partout dès qu’elles le peuvent. Cependant, nombreux sont les gadgets et autres programmes « intelligents » qui n’utilisent pas véritablement de l’IA.
Maintenant que nous comprenons un peu plus ce que font réellement les systèmes d’IA, nous pouvons identifier d’autres systèmes de ce type et les distinguer des programmes informatiques sophistiqués qui ressemblent à de l’IA mais n’en sont pas.
Résumons brièvement les principales caractéristiques de l’IA :
- Elle peut analyser un grand nombre de données.
- Elle trouve automatiquement des tendances et signaux faibles dans ces mêmes données.
- Elle utilise ces informations pour calculer les paramètres du modèle qui effectuera la tâche souhaitée de manière plus efficace.
Selon le modèle, votre montre « intelligente » ne l’est peut-être pas autant que vous le pensez. Afficher votre rythme cardiaque et compter le nombre de pas que vous faites chaque jour ne nécessite par exemple aucun système d’IA. Ces données peuvent être recueillies grâce à l’aide de simples capteurs bien réglés et bien positionnés.
Si elle vous donne ces chiffres sans les analyser plus en profondeur, votre montre n’a pas besoin de l’IA. Même lorsque votre appareil décide qu’il est temps de vous dire de vous lever et de bouger davantage, il n’a pas besoin d’IA. Il peut simplement utiliser ces mêmes capteurs pour mesurer votre temps d’inactivité et, à l’aide d’une règle, vous envoyer une alerte après 30 minutes par exemple.
Par contre, si votre montre analyse réellement vos activités et les utilise pour déterminer le moment optimal pour vous motiver, ou si elle analyse votre rythme cardiaque et identifie quelque chose d’irrégulier ou anormal, c’est qu’elle utilise un système d’intelligence artificielle.
Pour effectuer ces actions, votre appareil doit analyser vos données, identifier des tendances et corrélations qui vous sont uniques, et en déduire des paramètres, comme lorsque notre système d’IA l’a fait pour prédire le poids d’une personne.
Conclusion
Dans cet article, nous avons jeté un coup d’œil dans les coulisses de l’IA et exploré les moyens par lesquels cette technologie est capable de « fonctionner comme par magie ». Mais force est de constater que rien de tout cela ne relève de magie à proprement parler. En effet, c’est surtout le fruit d’une grande coopération entre un jeu de données et la capacité des systèmes d’IA à les analyser, à y trouver des tendances et à choisir les bons paramètres pour effectuer des tâches de façon efficace.
Dans le prochain article, nous verrons comment l’IA est capable de lire, d’observer et de prendre des décisions.
-
Cet exemple est inspiré du jeu de données National Health and Nutrition Examination Survey qui recense 60,000 individus. ↩
-
Cette définition des caractéristiques est inspirée du livre « Pattern recognition and machine learning » de Christopher Bishop. ↩
-
Pour en savoir plus sur Robert Wadlow, l’Homme le plus grand que connaisse l’Histoire, vous pouvez visiter cette page Wikipedia. ↩